Machine learning – Na identificação do câncer de mama

Introdução
O câncer de mama é uma das doenças mais prevalentes e impactantes em todo o mundo, afetando principalmente as mulheres, mas também pode afetar os homens. É uma condição na qual as células do tecido mamário se multiplicam de forma descontrolada, formando um tumor maligno. Trata-se de um problema de saúde pública significativo, com sérias implicações para a qualidade de vida e a mortalidade das pessoas afetadas. Este tipo de câncer é caracterizado por vários fatores, como o local de origem nas glândulas mamárias, a capacidade de se espalhar para outras partes do corpo, a diversidade de tipos histológicos e o potencial para diagnóstico precoce.
As causas do câncer de mama são multifatoriais e incluem fatores genéticos, hormonais, ambientais e de estilo de vida. A detecção precoce e os avanços na pesquisa médica têm desempenhado um papel fundamental na melhoria das taxas de sobrevivência e no desenvolvimento de tratamentos mais eficazes. Este câncer é notável não apenas por sua prevalência, mas também pelo impacto psicológico e emocional que tem nas pessoas afetadas e em suas famílias. O diagnóstico de câncer de mama é muitas vezes acompanhado de ansiedade, medo e incerteza. No entanto, com o apoio adequado, informações precisas e cuidados médicos apropriados, muitas pessoas conseguem enfrentar a doença com sucesso.
Descrição projeto
Nesse projeto de identificação de câncer de mama utilizando aprendizado de máquina (Machine Learning), o principal objetivo é desenvolver um sistema capaz de identificar possíveis casos de câncer e outras doenças relacionadas utilizando algoritmos de machine learning, tais como classificação, regressão logística e Naive Bayes. Ao final do projeto, e avaliar e comparar os melhores modelos de machine learning com base em métricas de desempenho. No entanto, é importante ressaltar que a escolha dos modelos de aprendizado de máquina ideais desempenha um papel crucial na tarefa de classificar doenças com precisão. Através da análise criteriosa e do ajuste de parâmetros, buscamos encontrar a combinação de algoritmos e técnicas que maximize a sensibilidade e a especificidade, a fim de garantir a detecção precoce e precisa de doenças, como o câncer de mama. Além disso, este projeto não se limita apenas à implementação de algoritmos, mas também envolve a coleta, pré-processamento e análise dos dados clínicos relevantes, garantindo a qualidade dos dados de entrada para o sistema de aprendizado de máquina. A integração de conhecimentos médicos e estatísticos desempenha um papel crucial na obtenção de resultados confiáveis.
Análise exploratória de dados
A análise de dados é o processo de inspecionar, limpar, transformar e modelar dados com o objetivo de descobrir informações úteis, extrair insights e tomar decisões informadas. É uma disciplina que envolve a aplicação de técnicas estatísticas, matemáticas e computacionais para explorar conjuntos de dados, identificar padrões, tendências e relações, e comunicar os resultados de forma compreensível. A análise de dados é amplamente utilizada em diversas áreas, incluindo negócios, ciência, tecnologia, saúde, finanças, marketing e muitas outras. Com o crescimento do volume de dados disponíveis atualmente, impulsionado pela digitalização e pela era da informação, a análise de dados tornou-se uma habilidade essencial para compreender e tomar decisões com base em informações.
– Gráfico barra
Neste gráfico de barras, é claramente evidente que o número de casos de câncer benigno é menor do que o número de casos de câncer maligno. Essa representação visual nos fornece uma compreensão imediata da distribuição dos resultados. É fundamental notar que a diferença na prevalência de câncer benigno e maligno é um fator relevante, pois influencia diretamente as estratégias de diagnóstico e tratamento empregadas na área médica. A análise desses dados é fundamental para tomadas de decisão informadas e abordagens eficazes no cuidado de pacientes.
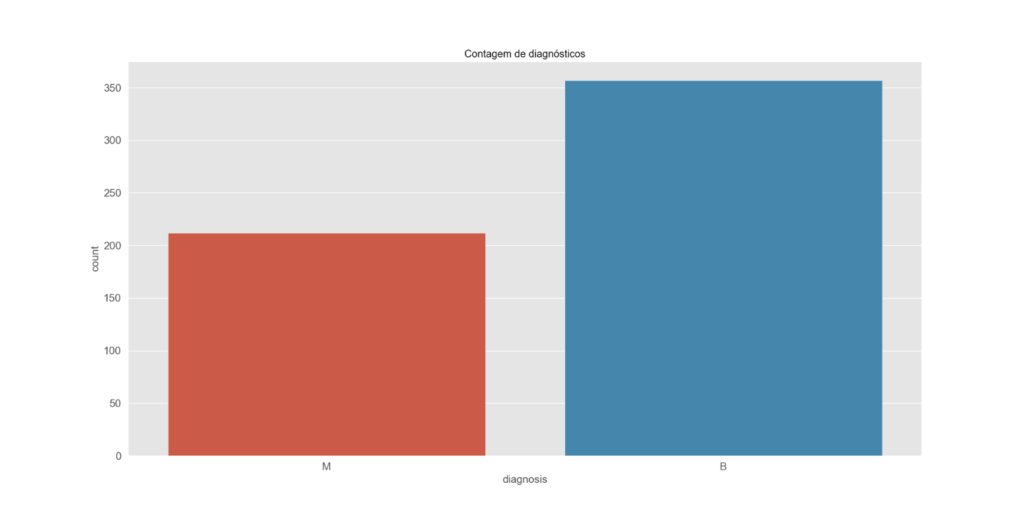
(Gráfico barras com a variável alvo)
– Gráfico media
A média de casos de câncer benigno se destaca, sendo maior do que a média de casos de câncer maligno. Isso indica que, em um conjunto de dados, a presença de casos de câncer benigno é mais comum do que a de câncer maligno. Essa disparidade na média entre os dois tipos de câncer tem implicações significativas em várias áreas, como estratégias de triagem e políticas de saúde.
É importante considerar que a diferença na prevalência de câncer benigno e maligno pode influenciar a alocação de recursos e o desenvolvimento de abordagens terapêuticas. Compreender essa relação estatística entre os tipos de câncer é essencial para orientar decisões clínicas e estratégias de prevenção, proporcionando uma visão mais precisa do cenário de saúde em questão.
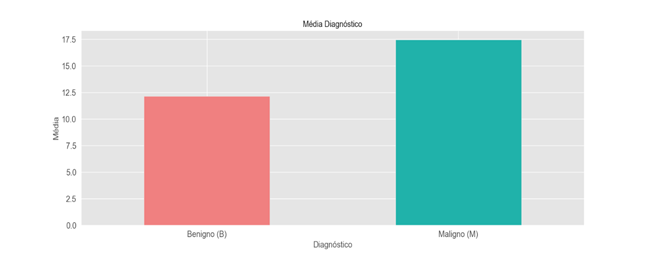
(Gráfico barras é medias)
– Gráfico correlação entre os dados
Nesse gráfico, podemos observar a correlação entre os dados presentes na base de dados. Através dessa representação visual, conseguimos identificar e analisar as relações e associações entre as variáveis presentes nos dados. Essa análise de correlação é fundamental para compreender como as diferentes variáveis se relacionam entre si e como influenciam os resultados.
A identificação de correlações é crucial em diversas áreas, como na pesquisa científica, na tomada de decisões de negócios e no campo da medicina. Ela permite a identificação de tendências e padrões que podem fornecer insights valiosos para a formulação de hipóteses, previsões e estratégias direcionadas. Portanto, a análise de correlação desempenha um papel importante na extração de conhecimento a partir dos dados.
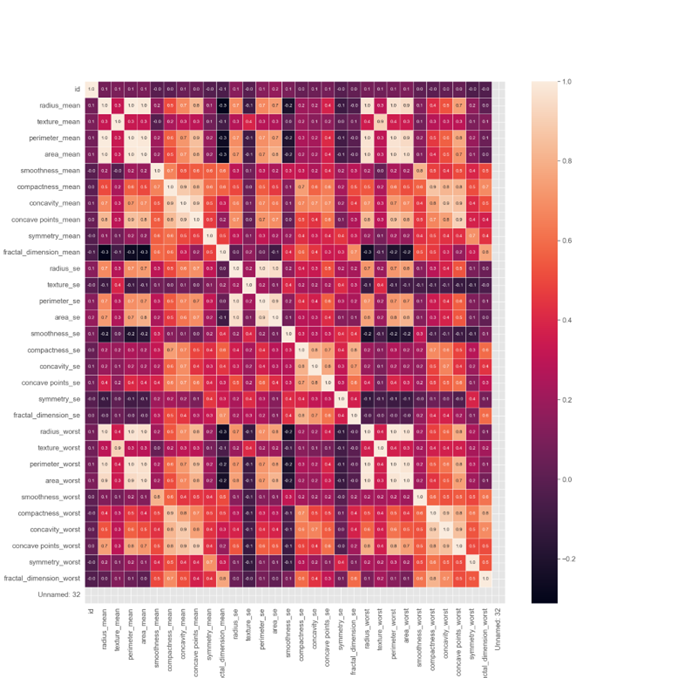
(Gráfico correlação)
– Gráfico boxplot
Neste gráfico, utilizamos um gráfico de boxplot como uma ferramenta valiosa para identificar possíveis outliers na variável-alvo. A detecção de outliers é um passo crítico na preparação dos dados para modelos de machine learning, uma vez que valores atípicos podem afetar significativamente o desempenho e a precisão desses modelos. Os outliers representam observações que estão significativamente afastadas do padrão geral dos dados. A identificação e o tratamento adequado de outliers são essenciais, pois podem levar a resultados distorcidos e predições imprecisas. Ao explorar o boxplot, podemos visualmente identificar valores que se afastam do intervalo interquartil e, assim, determinar se são candidatos a serem outliers.
A remoção ou o tratamento cuidadoso de outliers é uma etapa importante na preparação de dados para modelagem de machine learning, contribuindo para um modelo mais robusto e preciso. Portanto, a análise de boxplot desempenha um papel fundamental na garantia da qualidade dos dados utilizados no processo de aprendizado de máquina.
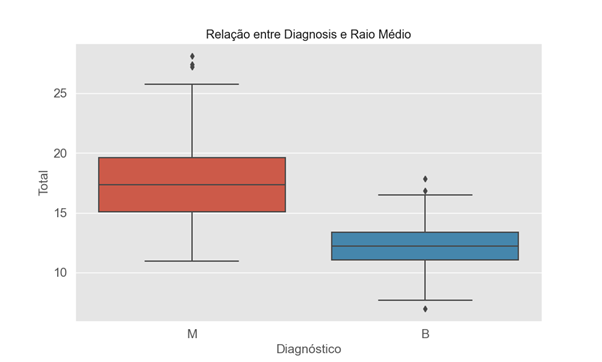
(Gráfico boxplot)
– Gráfico subplots
Nesse gráfico, podemos claramente identificar a presença de outliers, que são valores atípicos que se destacam do padrão geral dos dados. A detecção e o tratamento de outliers são etapas essenciais na análise de dados, pois esses valores atípicos têm o potencial de distorcer as análises estatísticas e comprometer a precisão dos modelos de machine learning. Além disso, ao utilizar subplots juntos com essa análise, podemos visualizar a extensão dos problemas de outliers que afetam diversas partes do conjunto de dados. Os subplots permitem uma abordagem mais detalhada, possibilitando a identificação de valores atípicos em diferentes segmentos dos dados. Identificar e compreender a natureza desses valores atípicos é crucial para adotar estratégias adequadas de tratamento, como remoção, transformação ou imputação, a fim de garantir que o modelo de machine learning seja robusto e capaz de fazer previsões precisas. A gestão eficaz dos outliers não apenas aprimora a qualidade dos dados, mas também contribui para resultados mais confiáveis e representativos em análises estatísticas e modelagem. Portanto, a identificação e o tratamento de outliers são aspectos críticos em qualquer projeto de ciência de dados ou análise estatística, e o uso de subplots pode aprimorar a capacidade de identificar e entender a distribuição desses valores atípicos em todo o conjunto de dados.
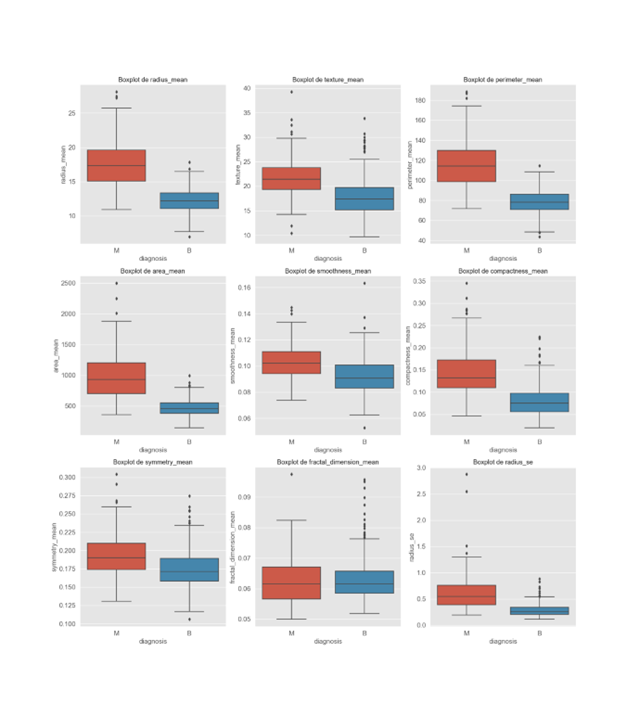
(Gráfico subplots boxplot)
Pré-processamento
O Label Encoder é uma técnica de pré-processamento de dados essencial, especialmente
quando se lida com a normalização de variáveis categóricas em projetos de machine learning. Variáveis categóricas representam categorias ou grupos, como “maçã”, “laranja” ou “banana”, em contraste com variáveis numéricas que expressam valores quantitativos. Dado que a maioria dos modelos de machine learning requer entradas numéricas, é crucial converter variáveis categóricas em formatos numéricos compreensíveis. O LabelEncoder é uma das abordagens mais comuns para atingir esse objetivo.
O LabelEncoder realiza essa tarefa atribuindo a cada categoria em uma variável categórica um valor numérico exclusivo. Por exemplo, se você tem uma coluna chamada “Fruta” com valores como “Maçã”, “Laranja” e “Banana”, o LabelEncoder atribuirá valores numéricos, como 0, 1 e 2, respectivamente, a essas categorias. Essa codificação numérica permite que os modelos de machine learning compreendam e processem essas variáveis categóricas de maneira eficaz.
No entanto, é importante notar que, ao usar o LabelEncoder, você deve estar ciente de que a atribuição de valores numéricos a categorias pode criar uma suposição de ordem que pode não ser apropriada para todos os conjuntos de dados. Portanto, em alguns casos, é necessário considerar técnicas adicionais, como a codificação one-hot, para evitar interpretações equivocadas e garantir uma modelagem precisa.
Normalização dados
A normalização de dados é um processo fundamental de pré-processamento amplamente aplicado na análise de dados e no campo do machine learning. Seu propósito é padronizar as variáveis, colocando-as em uma escala comum e uniforme. Esse procedimento é de extrema importância, uma vez que muitos algoritmos de aprendizado de máquina e técnicas estatísticas são sensíveis à escala das variáveis.
A normalização visa garantir que cada variável contribua de maneira equitativa e justa para a análise ou modelo em questão. Isso é particularmente relevante quando trabalhamos com conjuntos de dados que contêm variáveis em unidades diferentes ou em escalas variadas. Além de equalizar a influência das variáveis, a normalização também facilita a interpretação dos coeficientes e parâmetros dos modelos.
Ao realizar a normalização, as variáveis são ajustadas para uma faixa padrão, geralmente entre 0 e 1, embora outras escalas também possam ser usadas. Esse processo não apenas melhora o desempenho dos modelos de machine learning, mas também simplifica a compreensão e a análise dos dados, tornando-os mais comparáveis e interpretáveis.
Nesse processo de normalização de dados, fazemos uso da biblioteca de machine learning Scikit-Learn (Sklearn), em conjunto com a técnica do Label Encoder, para realizar a normalização de variáveis categóricas. Essas variáveis categóricas são frequentemente representadas por letras ou categorias, como “M” e “B”, e, para aprimorar a eficácia dos modelos, é necessário convertê-las em valores binários, tais como “1” e “0”. Isso é particularmente relevante em nossa coluna alvo.
O Label Encoder é empregado para atribuir valores numéricos às categorias, transformando “M” em “1” e “B” em “0”, por exemplo, para representar categorias binárias. Essa transformação é essencial em muitos contextos de machine learning, uma vez que os modelos frequentemente esperam entradas numéricas para realizar previsões precisas.
Essa normalização de dados desempenha um papel crítico na garantia de que os modelos sejam capazes de entender e interpretar adequadamente as variáveis categóricas, especialmente quando se tratam de variáveis categóricas binárias, como as utilizadas em nossa coluna alvo.
Portanto, o uso do Label Encoder junto com o Scikit-Learn é uma abordagem valiosa para a preparação de dados em projetos de machine learning.
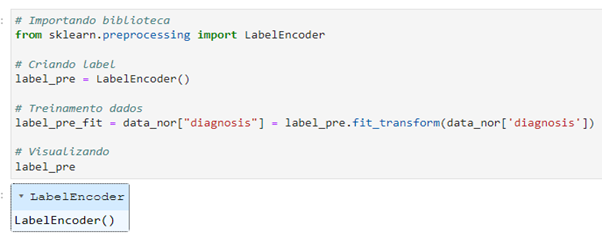
(Normalização dados utilizando label encoder do sklearn)
– Resultado normalização dados
Aqui, apresentamos o resultado da normalização, que é realizada por meio da aplicação do Label Encoder, transformando os dados em valores binários, ou seja, 0 e 1.
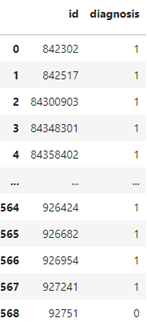
(Dados normalizados com Label Encoder)
Treino teste
O que é treino e teste ?
Treino e teste são duas etapas fundamentais no desenvolvimento de modelos de aprendizado de máquina (machine learning) e em outras técnicas estatísticas. Essas etapas são usadas para avaliar a capacidade de generalização do modelo e medir seu desempenho em dados não vistos anteriormente. A divisão entre treino e teste é necessária para evitar que o modelo memorize os dados de treinamento (overfitting) são elas.
1) Treinamento: Durante a etapa de treinamento, o modelo é alimentado com um conjunto de dados denominado conjunto de treinamento. Esse conjunto contém exemplos rotulados, onde as entradas (características) estão associadas a um rótulo conhecido (resultado esperado). O modelo usa esses exemplos para aprender os padrões e relações presentes nos dados e ajustar seus parâmetros internos. O objetivo do treinamento é encontrar os melhores parâmetros do modelo que minimizem a diferença entre as previsões do modelo e os rótulos conhecidos. Isso é feito por meio de algoritmos de otimização que ajustam gradualmente os parâmetros com base nas diferenças (erros) entre as previsões e os rótulos conhecidos.
2) Teste: Após o treinamento, é necessário avaliar o desempenho do modelo em dados não vistos anteriormente. Para isso, utiliza-se um conjunto de dados separado chamado conjunto de teste. Esse conjunto também contém exemplos rotulados, mas o modelo não teve acesso a eles durante o treinamento. O conjunto de teste é usado para fazer previsões com o modelo treinado e comparar essas previsões com os rótulos conhecidos. Isso permite medir a capacidade de generalização do modelo e avaliar seu desempenho em dados desconhecidos. Métricas como precisão, acurácia, recall e F1-score são comumente utilizadas para avaliar o desempenho do modelo durante a fase de teste.
É importante destacar que o conjunto de teste é usado apenas para avaliação final do modelo, não para ajustar seus parâmetros. A divisão entre conjunto de treinamento e conjunto de teste ajuda a estimar o desempenho esperado do modelo em situações reais, onde dados não rotulados estão disponíveis. Além do treinamento e teste, é comum também utilizar uma terceira etapa chamada de validação. Nessa etapa, um conjunto de dados separado chamado conjunto de validação é utilizado para ajustar os hiperparâmetros do modelo, como taxa de aprendizado, número de camadas, tamanho do batch, etc. A validação auxilia na seleção dos melhores hiperparâmetros antes de finalizar o treinamento e avaliar o modelo no conjunto de teste. A separação adequada entre treino, validação e teste é crucial para garantir uma avaliação justa e confiável do desempenho do modelo, além de evitar problemas de overfitting e subestimação de resultados.
Para desenvolver um modelo de previsão, é fundamental definir os conjuntos de treino e teste, utilizando a variável alvo ‘diagnosis’. Essa variável desempenha um papel essencial na capacidade do modelo de fazer previsões precisas
Divisão treino e teste
A divisão de treino e teste do modelo é uma etapa essencial na preparação dos dados. Aqui, estamos utilizando a coluna alvo ‘diagnosis’ para realizar essa divisão. No processo de treinamento, ‘x’ contém as características usadas para fazer previsões, enquanto ‘y’ representa a variável alvo ‘diagnosis’, que o modelo busca prever com base nessas características. Essa estratégia permite avaliar o desempenho do modelo e garantir sua capacidade de generalização para novos dados.
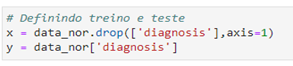
(Definição da variável alvo)
Treinamento modelo machine learning
O treinamento de um modelo de machine learning é um processo fundamental na construção de sistemas inteligentes. Durante o treinamento, o modelo é exposto a um conjunto de dados de treinamento que inclui exemplos passados e informações relevantes. Com base nesses dados, o modelo aprende a reconhecer padrões e a fazer previsões ou tomar decisões. Esse treinamento é essencial para que o modelo possa generalizar seu conhecimento e ser capaz de lidar com novos dados ou cenários. É um passo crucial no desenvolvimento de soluções baseadas em machine learning. Aqui, estamos dividindo os dados em 30% para treinamento e teste, utilizando uma divisão dos dados. Essa estratégia de divisão é fundamental para avaliar o desempenho do modelo e sua capacidade de generalização para novos dados. Dessa forma, reservamos 70% dos dados para treinamento e 30% para teste, garantindo que o modelo seja capaz de aprender com um conjunto de dados e, ao mesmo tempo, seja testado em dados não vistos anteriormente.
(Treinamento modelo machine learning)
Modelo machine learning
Um modelo de machine learning é um algoritmo ou conjunto de algoritmos que é treinado para realizar tarefas específicas, como classificação, regressão, clustering ou previsão, com base em dados. Esses modelos são uma parte fundamental da inteligência artificial e da aprendizagem de máquina, que são campos da informática que se concentram em criar sistemas que podem aprender e tomar decisões com base em dados, em vez de serem explicitamente programados para realizar tarefas. A ideia central por trás dos modelos de machine learning é que eles podem aprender a partir de exemplos e dados, em vez de depender de regras e programação explícita. Os modelos de machine learning são alimentados com conjuntos de dados de treinamento, nos quais eles procuram padrões e relações entre os dados. Depois de treinados, esses modelos podem ser usados para fazer previsões ou tomar decisões com base em novos dados. Existem vários tipos de modelos de machine learning, incluindo são os modelos:
– Modelos de regressão: Usados para prever valores numéricos a partir de dados, como prever preços de ações ou a temperatura.
– Modelos de classificação: Usados para atribuir categorias ou rótulos a dados, como classificar e-mails como spam ou não spam.
– Modelos de clustering: Usados para agrupar dados em clusters com base em semelhanças, como identificar grupos de consumidores com comportamentos semelhantes.
– Modelos de aprendizagem profunda (deep learning): uma subárea da aprendizagem de máquina que usa redes neurais artificiais com várias camadas para lidar com dados complexos, como imagens e texto.
Os modelos de machine learning são aplicados em uma ampla variedade de campos, incluindo medicina, finanças, marketing, visão computacional, processamento de linguagem natural e muito mais. Eles têm a capacidade de automatizar tarefas, melhorar a tomada de decisões e extrair informações úteis a partir de grandes volumes de dados.
Algoritmo XGBoost
XGBoost (Extreme Gradient Boosting) é uma implementação otimizada do algoritmo de gradient boosting que se destaca por sua eficiência e desempenho. Foi desenvolvido por Tianqi Chen como uma extensão da biblioteca Gradient Boosting Machine (GBM). O XGBoost é amplamente utilizado em competições de ciência de dados e aplicado em diversos problemas de aprendizado de máquina, como classificação, regressão e ranking. Ele se destaca por sua capacidade de lidar com grandes conjuntos de dados, alta velocidade de treinamento e melhorias em relação às implementações tradicionais de gradient boosting.
(Modelo XGBoost)
Aqui, o modelo XGBoost demonstrou uma notável eficácia quando comparado a outros modelos de machine learning, tais como Naive Bayes, Random Forest e Regressão Logística. Enquanto o Naive Bayes é conhecido por sua simplicidade e rapidez, o XGBoost superou-o em termos de desempenho e precisão. Além disso, em relação ao Random Forest, o XGBoost exibiu uma vantagem significativa na capacidade de lidar com conjuntos de dados complexos e variáveis interdependentes.
Já em comparação com a Regressão Logística, o XGBoost destacou-se pela sua capacidade de lidar com problemas de classificação não lineares e pela sua resiliência em face de outliers.
Assim, a escolha do XGBoost como modelo neste contexto revelou-se uma opção sólida e eficaz para a resolução deste desafio de machine learning.
– Feature
Aqui, as características mais importantes do modelo XGBoost desempenham um papel fundamental na compreensão do seu desempenho excepcional. O XGBoost sobressai ao destacar as features mais impactantes no processo de aprendizado, permitindo uma análise mais profunda e significativa. Por meio da identificação das features de maior relevância, é possível otimizar a modelagem e a tomada de decisões. Através dessa abordagem, o XGBoost proporciona uma vantagem competitiva ao destacar as características-chave que impulsionam o desempenho superior do modelo em relação a outros algoritmos de machine learning. Esse destaque nas features mais importantes do XGBoost é fundamental para a compreensão abrangente e aprimoramento contínuo do modelo.
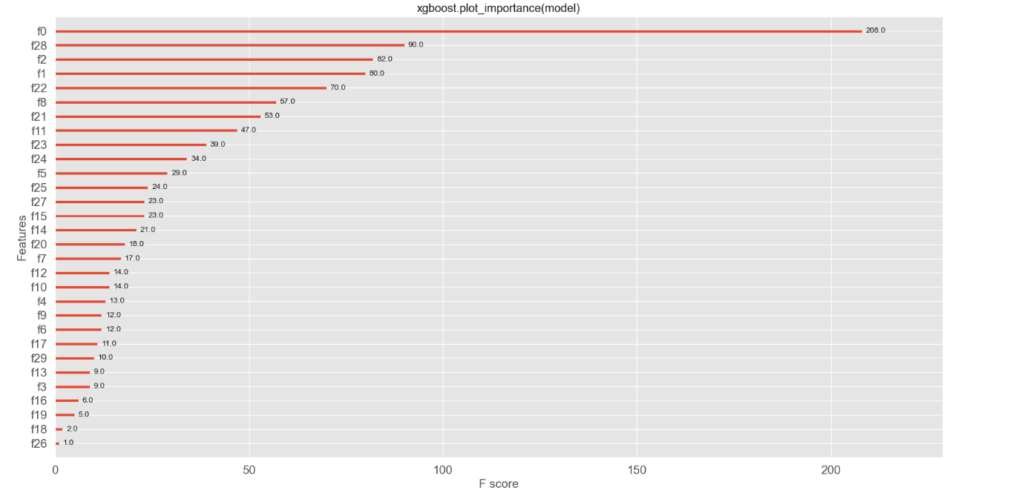
(Features modelo)
– Score do modelo
Aqui, ao analisarmos o score do modelo que obteve um impressionante desempenho com 100% de acerto, podemos claramente perceber a excelência e a eficácia desse modelo em particular. Esses resultados notáveis nos fornecem uma visão valiosa sobre como esse modelo se destacou em termos de precisão e confiabilidade. Além disso, ao compararmos esse modelo com outros, podemos ver como ele se destaca e supera os demais em termos de resultados. Essa conquista de 100% de acerto demonstra o potencial e a capacidade única desse modelo, ressaltando sua robustez e consistência. Portanto, a análise do score desse modelo é fundamental para compreendermos plenamente o seu desempenho excepcional em relação aos demais.
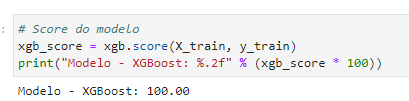
(Score do modelo)
– Previsão modelo
Aqui estão as previsões geradas pelo modelo XGBoost, apresentadas em formato binário (0 e 1). Vale ressaltar que o modelo não é capaz de processar valores em formato de strings, uma característica importante a ser considerada ao utilizar este algoritmo. As previsões em formato binário fornecem uma representação clara das classificações do modelo, em que ‘0’ pode indicar uma classe ou categoria específica, enquanto ‘1’ representa outra. Essa abordagem torna as previsões do XGBoost facilmente interpretáveis e úteis para uma variedade de aplicações, especialmente em problemas de classificação.
(Previsão modelo)
– Curva ROC
A Curva ROC (Receiver Operating Characteristic) é uma ferramenta valiosa para avaliar o desempenho do modelo, permitindo-nos observar como ele se comporta com os dados de treinamento. Essa curva é especialmente útil na análise da capacidade do modelo em distinguir entre classes ou categorias em um problema de classificação. Ela representa a relação entre a taxa de verdadeiros positivos (TPR) e a taxa de falsos positivos (FPR) em vários pontos de corte. Quando observamos a Curva ROC do modelo, podemos ter uma compreensão mais clara de como ele se comporta com os dados de treinamento. Quanto mais próxima a curva estiver do canto superior esquerdo, melhor será o desempenho do modelo, indicando uma alta capacidade de discriminação. Isso significa que o modelo está tomando decisões acuradas e minimizando os falsos positivos.
Portanto, a análise da Curva ROC é essencial para avaliar o poder discriminatório do modelo, permitindo-nos tomar decisões informadas sobre como ajustá-lo ou otimizá-lo para atender às necessidades específicas do problema de classificação em questão.
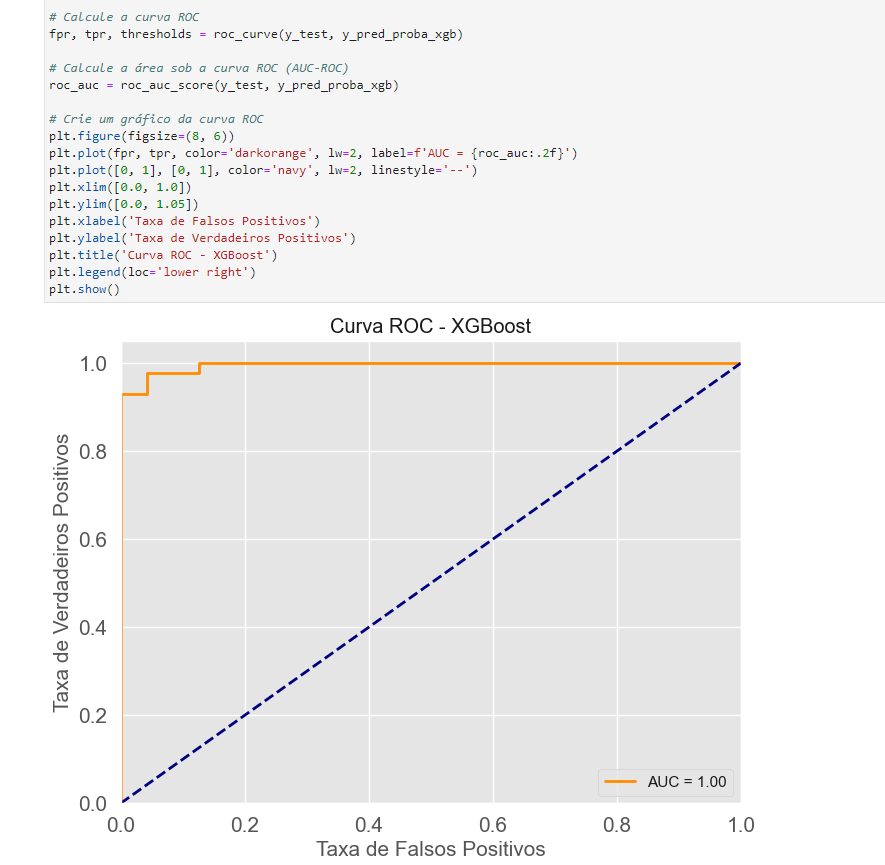
(Curva ROC)
– Acurácia
Aqui, a acurácia do modelo XGBoost atingiu um notável percentual de 95,61% de acerto em relação aos dados de teste. A acurácia é uma métrica fundamental que nos fornece uma medida geral do desempenho do modelo. Ela representa a proporção de previsões corretas em relação ao total de previsões feitas pelo modelo. A obtenção de uma acurácia de 95,61% demonstra a habilidade do modelo em fazer previsões precisas na maioria das vezes. No entanto, é importante ressaltar que a acurácia por si só pode não contar a história completa, uma vez que não leva em consideração possíveis desequilíbrios nas classes do problema de classificação. Portanto, ao interpretar a acurácia, é essencial considerar outras métricas e realizar uma análise mais abrangente do desempenho, como a Curva ROC, a Precisão e o Recall, dependendo das necessidades específicas do problema.
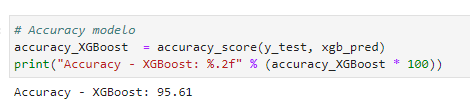
(Acurácia modelo)
– Classification report
O Classification Report fornece uma visão abrangente das métricas de avaliação do modelo, incluindo Precision (Precisão), Recall (Revocação), F1-Score e Support. Essas métricas são essenciais para uma análise detalhada do desempenho do modelo em tarefas de classificação.
- Precision (Precisão): A precisão representa a proporção de verdadeiros positivos em relação ao total de positivos previstos. É uma métrica que mede a precisão das previsões positivas do modelo.
- Recall (Revocação): O recall é a proporção de verdadeiros positivos em relação ao total de verdadeiros positivos mais falsos negativos. Essa métrica avalia a capacidade do modelo de identificar corretamente todos os casos positivos.
- F1-Score: O F1-Score é uma métrica que combina precisão e recall em um único valor, fornecendo uma medida equilibrada do desempenho do modelo. É especialmente útil quando há um desequilíbrio entre as classes.
- Support (Suporte): O suporte representa o número de amostras que pertencem a cada classe. Ajuda a entender a distribuição das classes no conjunto de dados.
A análise do Classification Report é crucial para avaliar o desempenho do modelo em detalhes e entender sua capacidade de fazer previsões precisas e identificar casos positivos. No caso do modelo avaliado, ele demonstrou um desempenho sólido, com pontuações positivas em todas essas métricas, o que é um indicativo de sua eficácia.
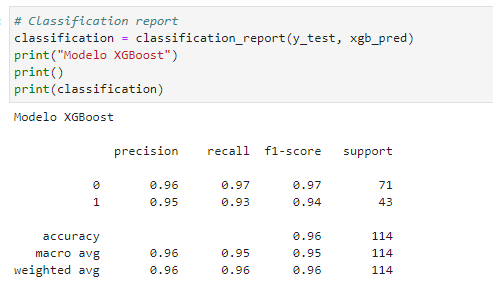
(Classification report)
– Matriz de confusão
Nessa matriz de confusão do modelo XGBoost, podemos analisar o resultado das previsões em relação à ocorrência da doença. Ela é composta por quatro elementos:
- Verdadeiros Positivos (VP): Isso representa os casos em que o modelo previu corretamente a presença da doença, e essas previsões estavam corretas. No caso do modelo, houve 69 verdadeiros positivos.
- Verdadeiros Negativos (VN): Os verdadeiros negativos são os casos em que o modelo previu corretamente a ausência da doença, e essas previsões estavam corretas. Aqui, houve 40 verdadeiros negativos.
- Falsos Positivos (FP): Os falsos positivos ocorrem quando o modelo prevê erroneamente a presença da doença, mas a condição real é a ausência da doença. No caso do modelo, ocorreram 2 falsos positivos.
- Falsos Negativos (FN): Os falsos negativos ocorrem quando o modelo prevê erroneamente a ausência da doença, mas a condição real é a presença da doença aqui, ocorreram 3 falsos negativos.
A matriz de confusão é uma ferramenta fundamental na avaliação do desempenho de modelos de classificação, permitindo a análise de como o modelo lida com diferentes cenários de previsão. Com base nesses elementos, é possível calcular diversas métricas de avaliação, como a Precisão, o Recall e o F1-Score, que nos ajudam a entender o quão eficaz o modelo é na detecção da doença. É importante interpretar e usar esses resultados para ajustar e otimizar o modelo, caso necessário, para obter o melhor desempenho possível
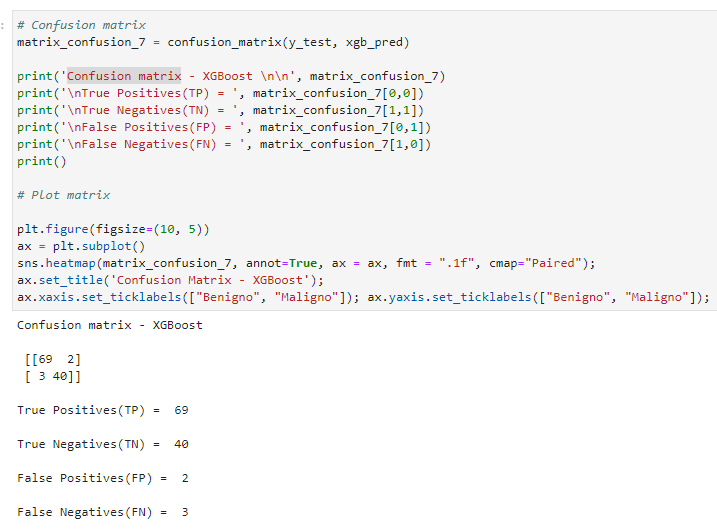
(Matriz de confusão)
– Plot matriz de confusão
Aqui, apresentamos o resultado da matriz de confusão na forma de um plot. A matriz de confusão é uma ferramenta crucial na avaliação de modelos de classificação, e o seu plot fornece uma representação visual dessa matriz, tornando a interpretação dos resultados mais acessível.
O plot da matriz de confusão é uma representação gráfica que permite visualizar de forma clara os verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos. Cada célula da matriz e sua cor podem destacar os acertos e erros do modelo, tornando fácil a identificação de onde o modelo está acertando e onde pode haver espaço para melhorias.
Essa representação gráfica é particularmente útil para comunicar os resultados a outras partes interessadas, pois é mais intuitiva do que examinar números isolados na matriz de confusão. Ao observar o plot da matriz de confusão, podemos ter uma visão imediata da performance do modelo, ajudando na tomada de decisões sobre ajustes, refinamentos ou ações necessárias para melhorar a capacidade do modelo de classificação.
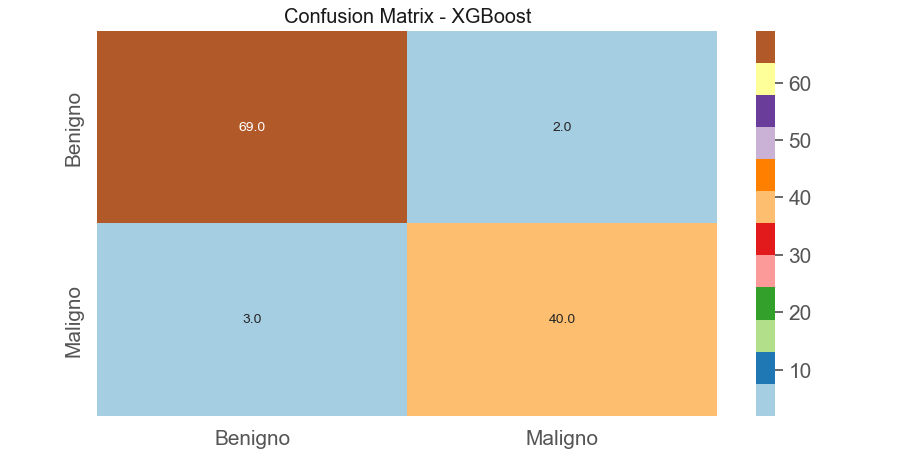
(Plot matriz de confusão)
Conclusão
Neste projeto de machine learning, com o uso do algoritmo XGBoost, alcançamos uma notável acurácia de 95%. Além disso, ao analisar a matriz de confusão, observamos 69 verdadeiros positivos e 40 verdadeiros negativos. Isso evidencia o potencial da inteligência artificial e do aprendizado de máquina e técnicas na área da saúde, em particular, na identificação e previsão de câncer de mama, utilizando algoritmos de machine learning.
Este artigo ilustra de forma convincente como a aplicação de técnicas de análise exploratória de dados, pré-processamento, normalização de dados, machine learning pode contribuir significativamente para melhorar a precisão e eficácia no diagnóstico e prognóstico de condições de saúde. A utilização dessas abordagens representa um avanço promissor no campo médico, proporcionando melhores resultados e impactando positivamente o cuidado e a prevenção de doenças, como o câncer de mama.
Referências
Pinheiro, Nina. “Pré-processamento de dados com Python.” Medium. Disponível em: https://medium.com/data-hackers/pr%C3%A9-processamento-de-dados-com-python-53b95bcf5ff4
Paula, Caíque de. “Um guia completo para o pré-processamento de dados em machine learning.” Medium. Disponível em: https://caiquecoelho.medium.com/um-guia-completo-para-o-pr%C3%A9-processamento-de-dados-em-machine-learning-f860fbadabe1
Aguiar, Alan de. “XGBoost — A matemática passo a passo.” Medium. Disponível em:
https://medium.com/@aln.deaguiar/xgboost-a-matem%C3%A1tica-passo-a-passo-29d34fa561dc
“XGBoost Documentation.” Disponível em: https://xgboost.readthedocs.io/en/stable/
Código github
Agradecimentos
- Categoria(s): Blog Ciências de dados Estatística Machine learning Saúde
Palavras relacionadas: cienciadedados, estatistica, machine learning