PREVISÃO DE SÉRIES TEMPORAIS VIA APRENDIZADO DE MÁQUINA EM ECOMMERCE DE GRANDE ESCALA UTILIZANDO TRANSFERÊNCIA DE APRENDIZADO E BOOSTRAP NÃO PARAMÉTRICO
Máiron César Simões Chaves
mairon.chaves@olist.com
Olist – Data Science and A.I. Department
April 24, 2024
Abstract:
This study presents a forecasting approach in e-commerce using LightGBM and transfer
learning to manage the complexity of a broad product catalog. Focused on optimizing the
overall RMSE and individual WMAPE evaluation, the model demonstrated remarkable
robustness: for SKUs with erratic demand, the median WMAPE was 36%, indicating reliability
even in the face of volatile sales that represent 10.19% of the SKUs. Products with intermittent
and lumpy demand, despite their inconsistencies, had median WMAPEs of 43% and 55%,
respectively, demonstrating the model’s adaptability. With exceptional performance, smooth
demand, representing 16.96% of the SKUs, achieved a median WMAPE of 27%. The strategic
use of non-parametric bootstrap to estimate confidence intervals improved the precision of the
forecasts, highlighting the value of the approach for consistent and reliable predictions in largescale scenarios.
Keywords Time Series · Transfer Learning · Retail · LightGBM · Forecasting
PREVISÃO DE SÉRIES TEMPORAIS ATRAVÉS DE APRENDIZADO DE MÁQUINA EM E-COMMERCE DE
GRANDE ESCALA
1. Introdução
A Olist, uma plataforma brasileira que conecta vendedores a múltiplos marketplaces, enfrenta desafios únicos de previsão devido à diversidade de SKUs que gerencia. A singularidade de cada SKU requer um sistema robusto de previsão adaptado a padrões de demanda variados, conforme descrito por Croston (2005): smooth, intermitente, errática e lumpy.
Empregamos métricas ADI e CV² para caracterizar e classificar esses padrões de demanda, essenciais na adaptação do nosso algoritmo de aprendizado de máquina – LightGBM – suportado por técnicas de engenharia de variáveis para prever vendas, incluindo dias sem demanda.
A introdução contínua de novos SKUs e a heterogeneidade dos dados impõem desafios significativos, superados por meio da seleção cuidadosa de dados. Este processo é validado e enriquecido por referências externas, como a competição de Precisão de Previsão M5.
Nossa metodologia visa não apenas atender às demandas da Olist, mas também enriquecer as práticas de previsão de demanda no e-commerce global. Aqui, o transfer learning surge como uma estratégia promissora, permitindo que um modelo pré-treinado com SKUs existentes seja rapidamente adaptado para novos produtos, fornecendo estimativas confiáveis de demanda desde o início de sua comercialização.
Embora a boa capacidade preditiva das previsões seja crucial, igualmente importante é a capacidade de quantificar a incerteza associada. Neste trabalho, empregamos uma adaptação do método de bootstrap em blocos para construir intervalos de confiança robustos que capturam a variabilidade inerente dos padrões de demanda e peculiaridades operacionais da Olist.
Sobre a empresa, a Olist é uma empresa brasileira que atua como uma ponte vital entre pequenos e médios vendedores e grandes marketplaces. Fundada em 2015, a empresa revoluciona o e-commerce ao facilitar a exposição de produtos de vendedores de diversos tamanhos em plataformas de alto alcance como Amazon e Mercado Livre, sem a complexidade e custo que normalmente isso envolveria. Através da plataforma da Olist, os vendedores podem gerenciar suas vendas, logística e atendimento ao cliente de forma centralizada, otimizando suas operações e aumentando sua visibilidade no mercado.
Além de sua principal atividade de e-commerce, a Olist faz parte de um grupo maior que inclui outras iniciativas e empresas focadas em resolver diferentes desafios do comércio digital. Essa diversificação de serviços reforça o compromisso da Olist em oferecer soluções abrangentes para o e-commerce, auxiliando os vendedores a alcançarem o sucesso em um mercado cada vez mais competitivo.
2. Métodos
2.1 Classificação dos padrões de demanda
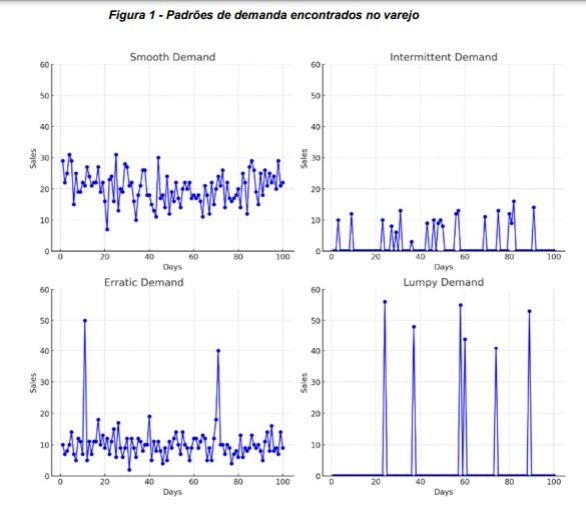
A pesquisa foi praticamente em sua totalidade, guiada pela proposta de Syntetos, Boylan e Croston (2005) onde diferenciamos as demandas dos produtos em quatro categorias fundamentais:
® Smooth: vendas regulares no tempo e regulares na quantidade de vendas – fácil para um algoritmo prever
® Intermitente: vendas irregulares no tempo, porém regulares na quantidade de vendas – séries temporais infladas de zero devido aos longos períodos sem venda
® Errática: vendas regulares no tempo, mas irregulares na quantidade de vendida – picos/vales abruptos
® Lumpy: vendas irregulares no tempo e irregulares na quantidade de vendida – alta complexidade de prever devido ao pouco ou nenhum padrão
ADI (Average Demand Interval) e CV² (square of the coefficient of variation) são duas métricas usadas para caracterizar e classificar padrões de demanda. ADI é uma medida que descreve a frequência média entre períodos de demanda positiva. A equação para calcular ADI em uma série temporal diária é:
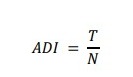
onde T é o número total de períodos observados e N é o número de períodos com demanda positiva (dias com vendas).
CV² (Coeficiente de Variação ao Quadrado) é uma medida que descreve a variabilidade relativa da demanda. É calculado como o quadrado do coeficiente de variação da demanda, que é a razão entre o desvio padrão e o valor médio da demanda, da seguinte forma:
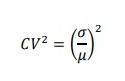
onde é o desvio padrão da demanda e μ é a demanda média.

Vamos visualizar um gráfico hipotético na figura 1, de como cada perfil geralmente se apresenta nos dados históricos:
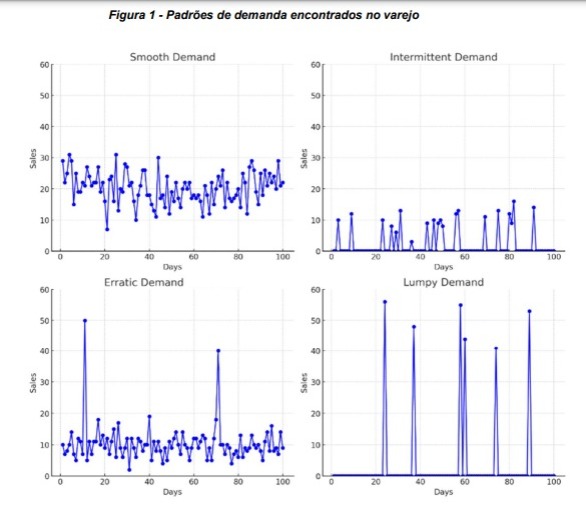
Essa classificação serve como base para nossa abordagem de modelagem e análise, pois cada tipo de demanda requer técnicas de previsão distintas. Em nosso caso, o objetivo é treinar um único algoritmo de aprendizado de máquina com dezenas de milhares de dados históricos, e o foco foi sem dúvida na engenharia de variáveis.
Analisamos cuidadosamente os quatro perfis de demanda e como poderíamos criar variáveis para fornecer informações suficientes para o algoritmo prever dias sem vendas no caso de produtos intermitentes, bem como lidar com variações abruptas de demanda para perfis lumpy e erráticos. Para esses três últimos perfis, o uso de intervalos de confiança é essencial porque a incerteza é significativa, enquanto para produtos com um perfil de demanda smooth, as previsões pontuais se mostraram adequadas.
2.2 Modelos Globais e Modelos Locais
Conforme apresentado por Montero-Manso e Hyndman (2021), os modelos globais, ao contrário dos modelos locais, aplicam uma única função de previsão a todas as séries no conjunto de dados, o que pode não ser mais limitante do que os métodos locais. Na verdade, os modelos globais podem replicar ou até superar o desempenho de previsão dos modelos locais sem assumir semelhança entre as séries.
Isso é possível devido à capacidade dos modelos globais de aprender padrões complexos e de longo prazo que só estariam disponíveis em modelos locais por meio de manipulações manuais ou suposições específicas. O método local individualiza a análise ao ajustar uma função de previsão para cada série temporal no conjunto de dados. Por outro lado, o método global adota uma abordagem unificada aplicando uma função preditiva comum a todas as séries temporais no conjunto de dados.
Contrariamente à percepção inicial, o método global revela uma capacidade equivalente aos métodos locais em termos de geração de previsões. Isso significa que as previsões obtidas por meio de métodos locais podem ser alcançadas por um modelo global e vice-versa. Essa equivalência é expressa da seguinte forma:
· Cada série temporal é representada por Xi, onde i identifica uma série específica dentro do conjunto de dados.
· A função de previsão para o método local é denotada como fi(Xi), enfatizando que uma função específica fi é ajustada para cada série individual Xi.
· Para o método global, usamos a função g(X), indicando uma única função preditiva g aplicada a todas as séries temporais. Portanto, podemos representar a equivalência entre os métodos da seguinte forma:
1. Para cada função global g, é possível identificar uma função local fi que gera previsões idênticas para a série Xi.
2. Da mesma forma, para cada função local fi, existe uma função global g que produz as mesmas previsões para Xi.
Essa equivalência é uma evidência promissora que ilumina o caminho para uma transição suave dos métodos locais tradicionais, como ARIMA e ETS, para modelos globais mais integrativos. Isso nos leva à conclusão de que o uso de um método global pode oferecer uma abordagem mais eficiente e escalável sem sacrificar a precisão da previsão em conjuntos de dados de séries temporais.
Portanto, uma estratégia não é necessariamente melhor do que a outra, mas uma pode ser preferível sobre a outra dependendo do contexto. Para profissionais acostumados com modelos locais, entender os modelos globais pode parecer desafiador inicialmente.
No entanto, esses modelos oferecem uma vantagem significativa em termos de escalabilidade e capacidade de generalização, especialmente útil em contextos com grandes conjuntos de dados e múltiplas séries temporais.
3. Coleta dos Dados
Os dados utilizados consistiam em séries temporais históricas de vendas de diferentes empresas dentro do grupo. Todas as séries temporais foram tratadas na granularidade diária, mas diferentes níveis de hierarquia de produtos foram utilizados. Cada unidade de corte transversal é um GTIN (Global Trade Item Number) ou SKU (Stock Keeping Unit). GTIN é um identificador para itens comerciais desenvolvido e controlado pela GS1[1] e SKU é um código de identificação único criado para organizar e classificar itens no estoque com base em suas características. Para simplificar a leitura do artigo, utilizaremos os termos GTIN e SKU de forma intercambiável.
Ao empilhar os dados, o identificador único para cada produto foi renomeado para ‘unique_id’.
3.1 Seleção de Séries Temporais Representativas
Após consolidar os dados, considerando três anos de histórico de janeiro de 2021 a janeiro de 2024, foi obtido um conjunto de dados contendo aproximadamente 20 milhões de produtos distintos.
Devido aos desafios mencionados na introdução, foi necessária uma metodologia para selecionar produtos cujas séries históricas sejam representativas em termos de variação e tamanho.
A presença predominante de produtos que compõem as chamadas ‘long tails’ do catálogo resulta em dados esparsos que são incompatíveis com as necessidades de modelos preditivos sofisticados. Além disso, diversos aspectos impedem de simplesmente adicionar todos os SKUs ao conjunto de dados de treinamento:
® Produtos que tiveram boas vendas no passado, mas pararam de vender meses atrás.
® Produtos com extrema intermitência, vendendo uma unidade hoje e, depois de dias, vendendo outra unidade.
® Produtos que vendem uma unidade e depois param de vender.
® Produtos que começaram a vender recentemente, portanto, têm muito pouco histórico de dados.
® Produtos com datas de início e término diferentes (séries temporais de comprimentos diferentes).
Foram testadas múltiplas estratégias de filtragem para seleção de séries temporais relevantes para o treino, mas será apresentada aquela que resultou em uma amostra mais representativa. Primeiramente, foi aplicado um filtro onde apenas produtos com trinta ou mais observações permaneceram no conjunto de dados.
Aqui, trinta datas não necessariamente implicam um mês, já que as datas têm lacunas. Um produto pode ser vendido em uma determinada data e só ter outra venda quinze dias depois, assim pode ter duas observações, uma no período t e outra no período t+15. Após esse filtro inicial, o número de produtos no conjunto de dados foi reduzido para aproximadamente um milhão e duzentos mil produtos.
Em seguida, foi aplicado um preenchimento de lacunas nas datas para garantir que todos os produtos tenham intervalos equidistantes. Por exemplo, se a primeira venda for no período t e a segunda venda for no período t+15, o processo de preenchimento de lacunas irá inserir as datas ausentes de t+1 a t+14 e preencher a quantidade de vendas com zeros, já que não houve vendas nessas datas.
Neste ponto, o conjunto de dados está no formato univariado, contendo três colunas no formato padrão usado pela biblioteca MLForecast para Python:
- unique_id: cada ID distinto representa um GTIN ou SKU.
- ds: é data da venda no formato yyyy-mm-dd.
- y: a quantidade vendida para o unique_id na data.
Essencialmente, temos um painel de séries temporais univariadas.
3.2 Filtragem de SKUs e Processo de Seleção de Dados
A seleção das séries temporais para análise detalhada foi baseada em dois critérios principais: demanda máxima e demanda diária média. Esses filtros foram estabelecidos para garantir que as séries temporais retidas para compor o conjunto de treinamento do algoritmo, não apenas estejam ativas, mas também sejam representativas de comportamentos ou fenômenos significativos.
- Demanda Máxima ≥ 6: O limite de 6 foi escolhido para identificar séries temporais que apresentam pelo menos um pico de atividade significativamente alto. Selecionar um pico mínimo garante a exclusão de séries que, apesar de consistentes, nunca atingem valores que indicam uma condição de estresse ou alta demanda.
- Demanda Diária Média > 1: Estabelecer um valor mínimo para a média diária de 1 garante que as séries mantenham uma atividade regular e sustentada. Este filtro é crucial para excluir séries que, apesar de terem picos isolados, são predominantemente inativas.
Aplicar esses critérios de filtragem direciona a análise para séries temporais que oferecem uma riqueza de dados em termos de intensidade e consistência. Isso não apenas melhora a qualidade das análises estatísticas e preditivas, mas também garante que os recursos computacionais e analíticos sejam otimizados para dados que têm mais probabilidade de revelar padrões significativos ou insights úteis.
Após essa filtragem, o número de produtos distintos (unique_id) reduziu para aproximadamente cento e cinco mil.
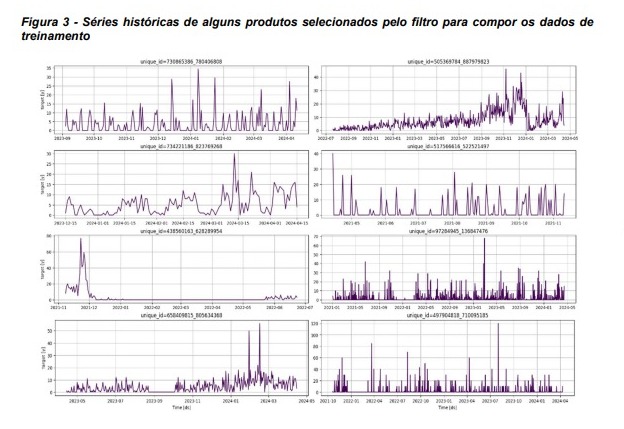
Cerca de cem mil unique_ids compuseram os dados de treinamento, gerando um conjunto de dados com pouco mais de 25 milhões de observações. Cinco mil unique_ids formaram o conjunto de validação, e as últimas 15 observações (equivalentes aos últimos 15 dias) de cada unique_id foram alocadas para o conjunto de teste. A lógica foi a seguinte:
- Treinar o algoritmo no conjunto de treinamento.
- Com o modelo treinado, analisar os dados históricos dos unique_ids no conjunto de validação e gerar previsões para 15 dias no futuro com base nisso.
- Avaliar as previsões durante o período de teste.
Como o objetivo é usar o transfer learning, o processo de treinamento do modelo foi direcionado para esse propósito. Durante mais de um ano de trabalho, foram realizadas análises exploratórias cuidadosas e pesquisas intensivas para construir variáveis que pudessem capturar o padrão de zeros frequentes em produtos com demanda intermitente. Desde o início, eu estava ciente da complexidade de modelar séries temporais erráticas e lumpys, mas variáveis exógenas foram cuidadosamente criadas para capturar suficientemente esses padrões de demanda .
É importante destacar que a empresa não ficou sem previsões durante o período em que este modelo estava sendo desenvolvido. Foram fornecidas alternativas interessantes utilizando modelagem hierárquica de top-down com a fantástica biblioteca fable para R, ajustando um modelo autorregressivo para a série temporal global e desagregando via método de proporção média histórica para níveis hierárquicos mais baixos[2]. Além disso, a biblioteca modeltime[3] em R também foi utilizada, proporcionando excelentes previsões. No entanto, devido a razões arquiteturais, uma solução em Python era necessária, e foi quando me deparei com o ecossistema Nixtla[4] e a biblioteca MLForecast.
3.3 Seleção de SKUs áptos para o transfer learning
Dessa forma, produtos que estão atualmente experimentando vendas e têm variação mínima entrarão no processo de previsão para que algum padrão possa ser detectado pelo Light GBM pré-treinado. Portanto, nem todos os SKUs registrados são adequados para previsão; filtros são aplicados a uma janela dos últimos 30 dias antes da data da previsão para garantir que o produto tenha um número mínimo de dias com vendas e uma variação mínima nas vendas para que algum padrão possa ser detectado pelo algoritmo pré-treinado.
Esse filtro resultou, para o período da experimentação que durou quinze dias, em aproximadamente 70 mil SKUs. Assim, de forma recursiva, a previsão é feita para os SKUs selecionados para 15 dias no futuro. Portanto, mesmo que um produto nunca tenha passado por uma data específica, como um feriado ou Black Friday, é altamente provável que durante o processo de treinamento, haja outros SKUs com padrões semelhantes a esse novo SKU, e assim, o algoritmo pode fornecer estimativas de demanda para o feriado ou Black Friday para este novo produto.
Esse método garante que o modelo global de machine learning seja capaz de generalizar bem para novos produtos, aproveitando os padrões aprendidos na etapa de treinamento por meio de SKUs com históricos mais ricos.
Além disso, buscamos referências externas para validar nossos métodos. A competição M5 Forecasting Accuracy, hospedada na plataforma Kaggle, é um benchmark útil. Os participantes desta competição enfrentam desafios semelhantes na previsão de vendas de produtos de varejo da cadeia Walmart, utilizando modelos que lidam com a complexidade e heterogeneidade dos dados. O uso bem-sucedido de variações de Gradient Boosting Machines (GBM) na competição M5 para prever a demanda dos SKUs do Walmart, me chamou a atenção para esse tipo de algoritmo.
4. Engenharia de Variáveis
No contexto de modelos globais para previsão de séries temporais, a incorporação de variáveis de defasagem (lags), variáveis móveis e variáveis de calendário assumem uma relevância estratégica.
As variáveis móveis nos modelos globais são calculadas por meio de uma janela deslizante que resume informações como médias, variâncias ou outras estatísticas, refletindo tendências locais ou ciclicidades dentro das séries temporais.
Já as variáveis de calendário; representam efeitos temporais específicos, como dias da semana, feriados ou estações, que influenciam consistentemente o comportamento das séries temporais.
4.1 Lags
Incorporar defasagens como preditores envolve aplicar valores de vendas de dias anteriores como ferramenta analítica para prever vendas futuras. Essa abordagem se baseia na premissa de que as vendas passadas contêm informações valiosas sobre tendências, padrões e ciclos que provavelmente se repetirão ao longo do tempo. Ao incorporar defasagens em um modelo de previsão, podemos obter insights sobre a dinâmica temporal dos dados, ajudando a capturar dependências de curto e longo prazo que influenciam o comportamento de vendas.
Matematicamente, isso significa que cada valor futuro 𝑦t da série temporal pode ser modelado como uma função dos valores anteriores 𝑦t-1, 𝑦t-2…,𝑦t-n onde n é o número de períodos de defasagem considerados. Essas defasagens atuam como variáveis explicativas que ajudam o modelo a entender melhor como as vendas em um dia são afetadas pelas vendas de dias anteriores, semanas ou até meses, dependendo da estrutura de defasagem.
Foram selecionados Lags Curtos (𝑦t-1, 𝑦t-2,𝑦t-3, 𝑦t-4, 𝑦t-5,𝑦t-6) para capturar a autocorrelação imediata, Lags Semanais(𝑦t-7, 𝑦t-14) múltiplos de sete dias, pois permitem ao modelo capturar padrões semanais e um Lag de Três Semanas (𝑦t-21), que é importante para capturar padrões de longo prazo. Assim, podemos representar as previsões ^yt como uma função de seus valores defasados:

Por fim, a complexidade computacional aumentada associada a lags maiores não necessariamente se traduz em uma precisão de previsão melhorada, tornando a restrição de lags uma decisão equilibrada entre capturar tendências de vendas e eficiência operacional. Portanto, a seleção cuidadosa de lags de até 21 dias visa maximizar o desempenho preditivo do modelo ao mesmo tempo que mantém a qualidade e a completude dos dados disponíveis.
4.2 Variáveis de Janelas Móveis
Características de janelas móveis são derivadas da variável de resposta y no tempo t e são incorporadas ao conjunto de dados como novas variáveis preditoras após a transformação. Esse processo enriquece o modelo com insights críticos sobre a dinâmica temporal das vendas.
Variáveis Criadas a partir de y no tempo t=1 (Lag 1)
1. Tendência Logarítmica
® Propósito: Captura tendências de longo prazo ao identificar crescimento ou declínio exponencial, especialmente valioso para produtos em fases de introdução ou declínio no mercado.
2. Médias Móveis em Diferentes Lags
® Propósito:
· Prazo Curto (Lags de 2 a 7 dias): Suaviza as flutuações diárias e enfatiza padrões semanais, benéfico para produtos com demanda estável.
· Prazo Médio (Lags de 14 e 21 dias): Revela tendências ao longo de várias semanas, crucial para entender produtos com demanda errática ou lumpy.
3. Mínimos e Máximos Móveis
® Propósito: Identifica valores extremos de vendas, crucial para capturar a volatilidade da demanda.
4. Desvios Padrão Móveis
® Propósito: Mede a dispersão das vendas em torno da média, indicando a variabilidade da demanda.
5. Diferenciais de Primeira e Segunda Ordem
® Propósito: Remove tendências e sazonalidades, enfatizando mudanças nas vendas. A diferenciação de primeira ordem fornece informações da magnitude e do sinal das variações e a diferenciação de segunda ordem traz informação de quão forte (ou fraca) as variações se apresentam.
6. Sazonalidade Diária (combinações de senos e cossenos)
A aplicação de funções senoidais e cossenoidais para modelar a sazonalidade diária é uma técnica poderosa que permite ao modelo de previsão capturar padrões cíclicos que se repetem em intervalos regulares. Essas funções são especialmente valiosas para identificar e se adaptar a flutuações que ocorrem em ciclos diários, semanais ou até mensais. Para cada dia, variáveis são criadas usando:

Variáveis Criadas a partir de y nos tempos t ≥ 2 a t ≤ 7 (Lag 2 até Lag 7))
Criar variáveis de janelas móveis que se iniciam em lags anteriores ao lag 1é bastante interessante para que o algoritmo de aprendizado de máquina possa capturar o movimento dos padrões durante a passagem dos lags impactando diretamente na qualidade das previsões. Foram utilizadas basicamente as mesmas variáveis que foram criadas a partir do lag 1, com alterações no comprimento das janelas móveis e redução da frequência da combinação de senos e cossenos.
4.3 Variáveis de Calendário
As variáveis de calendário são cruciais para capturar padrões temporais específicos que influenciam as vendas no e-commerce. Essas variáveis são implementadas como indicadores binários (0 ou 1), onde ‘1’ indica a presença de uma condição específica e ‘0’ indica sua ausência.
Aqui está uma descrição técnica de como cada variável de calendário é calculada:
- Dias da Semana
Cada dia da semana tem sua própria variável indicadora:
® Segunda-feira: Se o dia da semana for segunda-feira (dayofweek == 0), a variável é marcada como 1; caso contrário, é 0.
® Terça-feira: Se o dia da semana for terça-feira (dayofweek == 1), a variável é marcada como 1; caso contrário, é 0.
O mesmo padrão se aplica aos outros dias da semana.
- Meses do Ano
® Cada mês do ano tem sua própria variável indicadora. Por exemplo, a variável de janeiro é marcada como 1 se o mês atual for janeiro (month == 1); caso contrário, é 0. O mesmo padrão se aplica aos outros meses.
- Dias Úteis:
® Dia útil: A variável é marcada como 1 se o dia da semana for um dia útil (weekday < 5), indicando de segunda a sexta-feira, excluindo feriados; caso contrário, é 0.
- Semana da Black Friday
® A semana da Black Friday é identificada calculando a última sexta-feira de novembro. A variável é marcada como 1 para todos os dias dessa semana; caso contrário, é 0.
- Estações do Ano
® Verão: Marcado como 1 se a data estiver entre 21 de dezembro e 20 de março no hemisfério sul.
® Outono: Marcado como 1 se a data estiver entre 21 de março e 20 de junho.
® Inverno: Marcado como 1 se a data estiver entre 21 de junho e 22 de setembro.
® Primavera: Marcado como 1 se a data estiver entre 23 de setembro e 20 de dezembro.
4.4 Target Transform
A variável resposta (quantidade vendida) não foi utilizada diretamente; em vez disso, uma diferenciação de lag-7 foi aplicada anteriormente para preparar os dados para análise. Essa técnica é expressa matematicamente como:
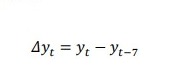
Essa fórmula ajusta cada ponto na série temporal subtraindo o valor de vendas do mesmo dia da semana anterior. Essa operação é crucial por várias razões matemáticas e analíticas.
A técnica de diferenciação, especificamente subtraindo de , é utilizada para mitigar os efeitos da sazonalidade semanal e promover a estacionariedade em séries temporais, características cruciais para modelos de previsão eficazes.
4.5 Seleção do Algoritmo
Na busca pelo modelo mais eficaz para prever a demanda em uma ampla variedade de produtos em um ambiente de e-commerce em grande escala, vários algoritmos de aprendizado de máquina foram testados, incluindo LightGBM, XGBoost, Random Forest, Autoregressive Multilayer Perceptron e K-Nearest Neighbors (KNN). Para o contexto específico da Olist, com aproximadamente 200 variáveis derivadas, incluindo 100 colunas exclusivamente para termos de Fourier (seno e cosseno), foi crucial selecionar um modelo que não apenas gerenciasse eficientemente um grande número de variáveis, mas também capturasse padrões de demanda diversos (smooth, errático, lumpy e intermitente).
4.6 LightGBM como modelo escolhido
Entre os modelos avaliados, os modelos baseados em árvores de decisões, especificamente o LightGBM, se mostrou promissor devido à sua capacidade de lidar com a complexidade e heterogeneidade dos dados. Além da excelente capacidade de capturar diferentes padrões de demanda.
O LightGBM é um framework de aprendizado de máquina para construir modelos de boosting baseados em árvores de decisão, particularmente eficiente para grandes volumes de dados. No caso do LightGBM, uma representação comum é o uso de boosting de gradiente, onde o modelo é construído adicionando árvores de forma iterativa para minimizar a função de perda. A equação básica para atualização de um modelo em cada iteração no boosting de gradiente, que também se aplica ao LightGBM, pode ser descrita da seguinte forma:

O LightGBM se distingue no manuseio de grandes conjuntos de dados devido a técnicas inovadoras como a Amostragem Unilateral Baseada em Gradiente (GOSS) e o Agrupamento Exclusivo de Recursos (EFB). O GOSS melhora a eficiência do treinamento ao focar em instâncias com erros maiores e amostrar aleatoriamente instâncias com erros menores, o que acelera a convergência e reduz o overfitting. O EFB aborda a alta dimensionalidade ao agrupar recursos mutuamente exclusivos, reduzindo a complexidade sem perder informações e melhorando a eficiência de processamento. Além disso, o LightGBM utiliza técnicas de gradiente baseadas em histograma para seleção automática de características importantes, otimizando a precisão de previsão e eficiência computacional, características essenciais para o processamento eficaz dos volumosos e complexos dados da Olist.
5. Ajuste de hiperparâmetros e métricas de avaliação.
Durante o desenvolvimento do modelo de previsão para a Olist, a eficiência do LightGBM permitiu que o processo de ajuste dos hiperparâmetros fosse menos intensivo em comparação com outros modelos, sem a necessidade de uso de GPU. Isso é atribuído ao design cuidadoso das variáveis preditoras e à seleção criteriosa dos produtos que compuseram o conjunto de dados. O ajuste fino das configurações do modelo concentrou-se principalmente na minimização do RMSE global, uma métrica que fornece uma avaliação do desempenho do modelo em diferentes magnitudes de demanda.
5.1 Métricas de avaliação
Root Mean Squared Error (RMSE) – Global:
O Root Mean Squared Error (RMSE) Global foi escolhido como a principal métrica durante o processo de ajuste devido à sua eficácia em quantificar o erro médio das previsões. Ao calcular o RMSE globalmente, com todas as previsões e valores reais agregados, podemos avaliar a capacidade do modelo de lidar com produtos de magnitudes de vendas variadas, desde baixas até muito altas. Essa abordagem ajuda a garantir que o modelo seja robusto e tenha um bom desempenho, independentemente das flutuações específicas de cada SKU. O RMSE pode ser descrito pela expressão matemática:


Coeficiente de Determinação (R²) – Global:
Além do RMSE, o coeficiente de determinação (R²) também foi utilizado no processo de ajuste para avaliar a qualidade das previsões. Globalmente, o R² é uma excelente métrica para compreender o quão bem as previsões se ajustam aos dados reais. Um R² alto indica que o gráfico de valores previstos versus originais se aproxima de uma linha reta, sinalizando previsões de alta qualidade. É importante notar que, embora o R² possa ser menos informativo quando analisado para uma série temporal individual (devido à sua sensibilidade a variações na média dos dados e no número de observações), em um contexto global, ele revela efetivamente a capacidade do modelo de prever consistentemente em diferentes produtos. O R² pode ser descrito pela expressão matricial:

Weighted Mean Absolute Percentage Error (WMAPE) – Local:
Após cada etapa de ajuste de hiperparâmetros, o WMAPE foi utilizado para avaliar as previsões individuais por produto. O WMAPE é especialmente valioso em cenários de e-commerce, pois pode lidar com vendas zero, frequentemente causadas pela intermitência de alguns produtos. Essa métrica fornece uma medida de erro percentual facilmente interpretável pelas áreas de negócio, destacando a proporção do erro em relação às vendas reais e permitindo ajustes mais focados nas previsões. O WMAPE pode ser descrito pela seguinte expressão:

Aqui está um pseudo-algoritmo para ilustrar o processo do treino até o momento do cálculo das métricas globais:
1. Inicialize o modelo
2. Defina os conjuntos de dados de treinamento e validação
2.1. No conjunto de validação, separe os últimos 15 dias para o conjunto de teste
3. Treine o modelo com os dados de treinamento
4. Para cada produto no conjunto de dados de validação:
4.1. Aplique o modelo treinado nos dados de validação para fazer previsões 15 dias no futuro
4.2. Utilize os 15 dias contidos nos dados de teste para comparar com os 15 dias previstos para o futuro
5. Empilhe as previsões e os valores reais dos últimos 15 dias, independentemente do produto e calcule o RMSE e o R-quadrado entre as previsões e os valores reais
Para o treinamento do modelo, foi utilizada uma instância com 96 CPUs e 384 GiB na Amazon SageMaker. E note que o processo envolve três conjuntos de dados, treino, validação e teste, o RMSE e o R2 são computados nos dados de teste e comparando-os com as previsões.
5.2 Hiperparâmetros avaliados
Ao desenvolver modelos globais para previsão de demanda, a seleção e ajuste de hiperparâmetros são cruciais para garantir que o modelo seja preciso e eficiente. Abaixo, detalho as propriedades técnicas dos hiperparâmetros ajustados durante a sintonização, focando em como cada um influencia o desempenho do modelo no contexto de previsão de vendas em larga escala, como no caso da Olist.
Tabela 1 – Hiperparâmetros do LightGBM que foram avaliados
| Hiperparâmetro | Descrição | Propriedades Técnicas |
| Número de Estimadores (n_estimators) | Representa o número de árvores sequenciais a serem construídas no modelo. | Balança complexidade com risco de overfitting; aumenta estabilidade, mas eleva custo computacional. |
| Taxa de Aprendizado (learning_rate) | Controla a contribuição de cada árvore para o modelo final, afetando a rapidez com que o modelo aprende. | Taxas menores melhoram a convergência e podem exigir mais árvores, prolongando o treinamento. |
| Profundidade Máxima (max_depth) | Limita o número de níveis nas árvores de decisão. | Limita overfitting ao controlar profundidade; essencial para a generalização eficaz. |
| Número de Folhas (num_leaves) | Define o número máximo de folhas (nós terminais) que cada árvore pode ter. | Mais folhas aumentam flexibilidade e risco de overfitting; equilíbrio necessário para complexidade do modelo. |
| Peso Mínimo por Filho (min_child_weight) | Define a soma mínima dos pesos de todas as observações necessárias em um filho (nó de divisão). | Previne divisões insignificantes, controlando overfitting e ajustando a complexidade da árvore. |
| Regularização (reg_alpha, reg_lambda) | Parâmetros de regularização L1 (reg_alpha) e L2 (reg_lambda) que ajudam a controlar o overfitting penalizando modelos mais complexos. | Suaviza a função objetivo e estabiliza o aprendizado; ajustes necessários para manter eficácia. |
| Subsample | Define a fração de amostras a serem usadas para treinar cada árvore individual dentro do modelo em conjunto. | Reduz overfitting ao variar subconjuntos de dados; aumenta diversidade e robustez do modelo. |
| Colsample_bytree | Especifica a fração de características a serem usadas para treinar cada árvore. | Limita características por árvore para prevenir overfitting e melhorar desempenho em conjuntos de alta dimensionalidade; promove diversidade entre árvores. |
5.3 Construção de Intervalos de Confiança via Boostrap
Para construir intervalos de confiança robustos para previsões de demanda na Olist, foi empregada uma adaptação do método de bootstrap em blocos.
Descrição do Processo de Bootstrap em Blocos
O método de bootstrap em blocos foi adaptado para acomodar as peculiaridades das séries temporais de vendas de produtos, seguindo estes passos fundamentais:
- Definição do Tamanho do Bloco e Número de Reamostragens: A série temporal de cada produto é dividida em k blocos de tamanho fixo, nesse cenário, cada bloco contém 7 observações consecutivas, assim, preservando a dependência temporal semanal dentro de cada bloco.
- Reamostragem dos Blocos: Durante o processo de bootstrap, blocos são selecionados aleatoriamente com reposição. A seleção aleatória de blocos ajuda a simular diferentes cenários temporais enquanto mantém a estrutura interna dos blocos, crucial para a integridade da dependência temporal das observações.
- Reconstrução da Série Temporal: Após a reamostragem, os blocos selecionados são concatenados para formar novas séries temporais. Essa reconstrução garante que cada série bootstrap mantenha uma sequência temporal coerente, crucial para análises subsequentes.
- Ajuste dos Identificadores de Série: Cada série temporal reamostrada é atribuída um identificador único, permitindo distinguir entre diferentes iterações de bootstrap. Isso é essencial para construção dos intervalos de confiança para cada produto.
5. Cálculo do Intervalo de Confiança: Após gerar as séries reamostradas, o modelo de previsão é aplicado a cada uma delas para produzir previsões futuras. Intervalos de confiança são então calculados a partir das distribuições das previsões reamostradas, geralmente usando percentis para definir os limites superior e inferior.
5.4 Transferência de Aprendizado (transfer learning)
Transfer learning é uma técnica avançada onde um modelo desenvolvido para uma tarefa específica é adaptado para uma nova tarefa relacionada. Este método é altamente valorizado no contexto de deep learning, onde modelos extensivamente treinados em grandes conjuntos de dados são posteriormente refinados para tarefas mais especializadas. A ideia central é o LightGBM pré-treinado com dezenas de milhões de padrões, seja capaz de prever as vendas de produtos que não estavam no seu conjunto de treino, devido a sua alta capacidade generalização.
Aplicação na Previsão de Demanda
Metodologia Recursiva “um-passo-à-frente”

6. Resultados
Este capítulo é dedicado a examinar os resultados obtidos a partir da aplicação de técnicas avançadas de aprendizado de máquina para previsão de demanda na plataforma de e-commerce Olist. Através de uma fase rigorosa de engenharia de variáveis e do ajuste dos hiperparâmetros, buscamos otimizar o modelo LightGBM para alcançar a melhor capacidade preditiva possível.
A figura subsequente ilustra a relação entre a configuração de hiperparâmetros e seus respectivos valores de RMSE. Cada subplot representa a variação do RMSE em relação a um hiperparâmetro específico, proporcionando uma perspectiva detalhada de como o ajuste fino pode influenciar a precisão das previsões de demanda ao avaliar 100 combinações distintas de parâmetros.

A configuração com o desempenho mais promissor foi a seguinte:
Tabela 2 – Resultado do ajuste dos hiperparâmetros
| Hiperparâmetro | Valor |
| n_estimators | 600 |
| learning_rate | 0.1 |
| max_depth | 12 |
| num_leaves | 90 |
| min_child_weight | 0.05 |
| reg_alpha | 1.2 |
| reg_lambda | 1.0 |
| subsample | 0.8 |
| colsample_bytree | 0.7 |
Resultando em um RMSE de 39,49, indicando uma estimativa de erro significativamente reduzida, e um R² de 78,77%, refletindo uma forte correlação entre os valores previstos e os valores reais.
6.1 Variáveis mais relevantes
A seguir, apresentamos uma análise da importância das variáveis, revelando o peso de cada característica nas previsões do modelo LightGBM. Essa análise não apenas nos permite identificar as variáveis mais influentes, mas também ajuda a esclarecer como diferentes informações contribuem para entender a dinâmica de vendas na Olist.
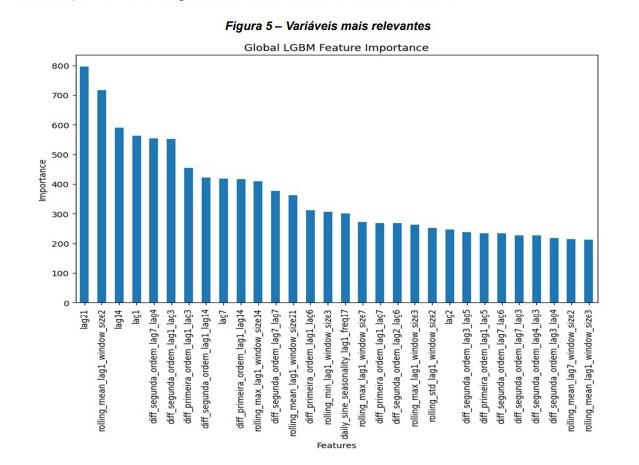
Ao avaliar a importância das variáveis no modelo global do LightGBM para prever as vendas de vários SKUs, identificamos uma predominância de variáveis de diferenciação de primeira e segunda ordem. A diferenciação é uma técnica poderosa em modelagem de séries temporais usada para transformar dados não estacionários em estacionários, revelando tendências ocultas e padrões cíclicos que são cruciais para previsão.
A diferenciação de primeira ordem, representada no modelo por variáveis derivadas de diferentes lags (como ‘lag1’, ‘lag14’, ‘lag21’), calcula a diferença nas vendas entre dois pontos consecutivos no tempo. Essa transformação destaca a variação imediata nas vendas, capturando a volatilidade diária e semanal e permitindo que o modelo detecte a inércia na série temporal — um indicador crucial de tendências de curto prazo.
A significativa presença de variáveis de diferenciação de segunda ordem sugere que o modelo está capturando não apenas mudanças nas vendas, mas também mudanças nas próprias mudanças — efetivamente, a aceleração ou desaceleração nas vendas.
Isso é especialmente evidenciado pela variável de segunda ordem construída a partir do ‘lag7’ com uma janela de 4 dias. A aceleração capturada reflete oscilações nas vendas que não são aparentes ao observar apenas as vendas diárias ou as diferenças de primeira ordem. Detectar essa aceleração é crucial para identificar pontos de virada no comportamento de compra, que podem anteceder eventos significativos como promoções ou mudanças sazonais.
Aplicar essas técnicas de diferenciação em várias janelas de tempo permite que o modelo LightGBM se adapte a padrões de vendas com diferentes frequências e magnitudes. Janelas menores focam em efeitos de curto prazo e flutuações imediatas, enquanto janelas maiores permitem capturar tendências de longo prazo e ciclos mais extensos.
Além disso, integrar essas variáveis de diferenciação com diferentes defasagens permite uma modelagem mais robusta, já que diferentes produtos podem ter ciclos de vendas distintos. Portanto, um lag que capture o comportamento de vendas de um SKU específico pode não ser a mesma para outro, e a diferenciação ajuda a ajustar o modelo para essa heterogeneidade.

6.2 Análise de resíduos
Na figura subsequente, apresentamos histogramas dos resíduos associados a quatro padrões diferentes de demanda.
Cada histograma fornece uma visualização concreta da distribuição dos erros de previsão, permitindo-nos avaliar o quão bem o modelo está se ajustando aos dados. Idealmente, buscamos uma distribuição de resíduos o mais próxima possível de uma distribuição normal, indicando que o modelo está capturando todas as informações relevantes e deixando apenas o ruído aleatório inerente ao processo de vendas. A distribuição dos resíduos em um modelo de previsão nos diz muito sobre possíveis vieses de subestimação e/ou superestimação das previsões. O cenário ideal é que os resíduos sejam normalmente distribuídos centrado em zero.

A demanda lumpy, com sua tendência a padrões quase aleatórios e picos imprevisíveis, serve como uma prova substancial da robustez do modelo; o fato de que a assimetria dos resíduos é mantida tão próxima de zero é por si só uma façanha, refletindo um equilíbrio notável nas previsões que muitas vezes podem ser inerentemente flutuantes.
A demanda errática, frequentemente marcada por variações abruptas repentinas, apresenta um desafio distinto para qualquer algoritmo preditivo. Apesar disso, o modelo consegue manter uma distribuição de erros extraordinariamente centrada, como evidenciado pela assimetria praticamente negligenciável. Isso é uma clara indicação da capacidade do modelo de lidar com a volatilidade sem introduzir viés sistemático, o que é especialmente impressionante dada a incerteza inerente a esse tipo de padrão de demanda.
Quanto à demanda intermitente, que inclui o desafio de prever dias consecutivos de vendas zero, mostra que mesmo diante dessa dificuldade, o modelo pode fornecer resultados com confiança razoável. A ocorrência de previsões precisas nesse cenário destaca a precisão analítica do modelo. A inclinação modesta para a superestimação indica que o modelo permanece otimista quanto à possibilidade de vendas, isso ocorre devido ao fato de que esse padrão de demanda é marcado por longos dias sem venda, e o modelo acaba prevendo, em alguns momentos, alguma venda quando na verdade não teve nenhuma, mas isso pode ser uma qualidade preferível em muitos contextos de negócios e planejamento.
Por fim, a demanda smooth, que poderia ser vista como o perfil mais previsível, revela por meio dos resíduos que o modelo está atento às nuances dessa categoria, adaptando-se e respondendo com precisão às suas variações sutis. A curtose indica que o modelo está preparado para capturar tanto dias comuns quanto eventos extraordinários, proporcionando uma base confiável para previsões consistentes.
Em resumo, os resultados alcançados reforçam a adaptabilidade e a precisão do modelo diante da complexidade multifacetada do comportamento da demanda.
6.4 Avaliação das previsões pontuais para cada produto
A distribuição de WMAPE por perfil de demanda destaca um panorama encorajador das capacidades preditivas do modelo, especialmente considerando a colossal incerteza que caracteriza o varejo em grande escala.

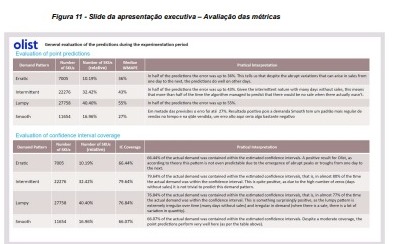
Para as demandas erráticas, que representam 10,19% do total de SKUs, vemos que a mediana do WMAPE é de 36%. Isso indica que, apesar das variações abruptas nas vendas, metade do tempo o modelo prevê com um erro de até 36%. Este é um resultado positivo, sugerindo que mesmo em tempos de alta volatilidade, o modelo se sai muito bem.
Nos produtos com demanda intermitente, correspondendo a 32,42% dos SKUs, a mediana do WMAPE de 43% reflete a robusta adaptabilidade do modelo. Considerando que muitos desses produtos podem não registrar vendas em vários dias, o resultado mostra que o modelo consegue capturar e prever com precisão a intermitência da demanda, um aspecto essencial em um ambiente com uma ampla gama de produtos com esse padrão de demanda.
Para produtos com demanda lumpy, compondo 40,40% dos SKUs, a mediana do WMAPE é de 55%. Isso é evidência de que o modelo está lidando bem com o que pode ser o padrão de demanda mais complexo devido à sua natureza imprevisível tanto em timing quanto em volume de vendas.
Por fim, os produtos com demanda smooth representam 16,96% dos SKUs, apresentaram um WMAPE mediano de 27%. Este resultado sugere que o modelo se sai excepcionalmente bem neste perfil, demonstrando sua capacidade de seguir um padrão regular de vendas mesmo em um ambiente onde a demanda pode flutuar.
Ao considerar a cobertura do intervalo de confiança (IC), temos mais motivos para otimismo. A cobertura do IC para demandas erráticas é de 66,44%, para demandas intermitentes é de 79,64%, para demandas lumpy é de 76,84% e para demandas smooths é de 66,07%. Estes números nos contam uma história interessante: na maioria dos casos, a demanda real está dentro dos intervalos estimados.
Para a Olist, isso significa que mesmo que prever picos e vales abruptos seja desafiador, o modelo está preparado para absorver e lidar com essas variações sem comprometer a confiança geral em suas previsões. Esses WMAPEs locais foram obtidos ao maximizar o RMSE global no processo de ajuste de hiperparâmetros.
Com essas informações, podemos dizer que a Olist possui um modelo preditivo que não apenas enfrenta o desafio de um ambiente de varejo incerto e variado, mas também se destaca por sua capacidade de produzir previsões confiáveis e acionáveis, crucial para decisões estratégicas de negócios, gerenciamento de estoques e planejamento operacional. É uma abordagem preditiva que se adapta e responde às complexidades do e-commerce, provando ser uma ferramenta valiosa na maximização da eficiência operacional e satisfação do cliente. Podemos ter uma visão das previsões 15 dias à frente em comparação com as vendas reais no nível SKU.
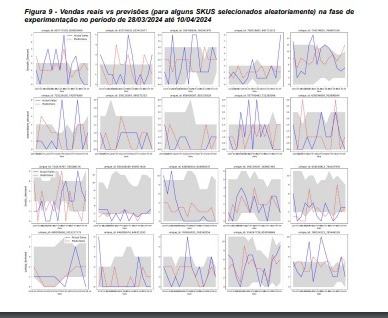
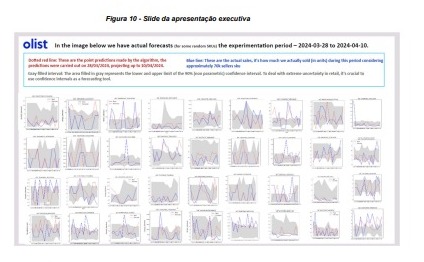
Podemos também visualizar os resultados resumidos que foram apresentados na reunião executiva de apresentação do modelo na empresa.
Na figura 11, temos um resumo das previsões avaliadas pela mediana do WMAPE, divididas por perfil de demanda, e também a cobertura do intervalo de confiança, também por tipo de demanda. Afinal, perfis mais complexos como intermitente, lumpy e lumpy têm incertezas significativas, então a assistência de intervalos de confiança para tomada de decisão é crucial. Além disso, também foi apresentado a cobertura do intervalo de confiança, ou seja, o percentual das vezes em que a demanda real estava contida no intervalo de confiança gerado.
7. Conclusões
Este estudo contribuiu significativamente para o campo da previsão de demanda no comércio eletrônico ao empregar uma abordagem inovadora de aprendizado de máquina usando LightGBM, complementada por técnicas de transfer learning e bootstrap não paramétrico. A pesquisa abordou os desafios únicos apresentados pela diversidade de SKUs gerenciados pela plataforma Olist, enfatizando a necessidade de um sistema de previsão de demanda robusto e adaptável. Os resultados destacam a eficácia do modelo em lidar com esses desafios, demonstrando confiabilidade e adaptabilidade em diversos cenários de vendas e ressaltando o uso estratégico do bootstrap para administrar a incerteza das vendas.
O sucesso do modelo foi evidenciado não apenas pela otimização do RMSE global, mas também pelo desempenho individual dos SKUs, refletido nas medianas do WMAPE, que foram consideráveis mesmo para SKUs com demanda errática e intermitente. O modelo se mostrou excepcionalmente eficiente para a demanda smooth que representam uma fração significativa dos SKUs. Essa eficiência é um claro indicador de que a abordagem adotada está alinhada com as operações de comércio eletrônico em grande escala, fornecendo um modelo robusto que pode ser aplicado a diferentes padrões de demanda.
As técnicas empregadas neste estudo, especialmente o uso de transfer learning, mostram grande promessa para implementação em cenários de previsão de vendas para outros produtos ou serviços no comércio eletrônico. Ao lidar com a heterogeneidade, a abordagem utilizada aqui estabelece um referencial metodológico que pode ser explorado em pesquisas futuras e aplicações práticas. A adaptabilidade do modelo é crucial em um mercado em constante mudança, onde a capacidade de responder rapidamente às tendências do consumidor é fundamental para o sucesso dos negócios.
Em resumo, o estudo validou a aplicação de um modelo global de aprendizado de máquina na previsão de demanda do comércio eletrônico, fornecendo um caminho para previsões consistentes e confiáveis. O uso do bootstrap não paramétrico e do transfer learning através do LightGBM surgiu como um avanço metodológico que garante previsões suficientemente precisas e adaptáveis, essenciais para operações estratégicas e competitividade no comércio eletrônico em grande escala.
8. Referências bibliográficas
Yi, S. (2023). Walmart Sales Prediction Based on Machine Learning. Highlights in Science, Engineering and Technology.
LIGHTGBM. Oficial Documentation: https://lightgbm.readthedocs.io/
MONTERO-MANSO, Pablo; HYNDMAN, Rob J. Principles and Algorithms for Forecasting Groups of Time Series: Locality and Globality. Sydney: University of Sydney; Monash University, 30 mar. 2021.
Raizada, S., & Saini, J. R. (2021). Comparative Analysis of Supervised Machine Learning Techniques for Sales Forecasting. International Journal of Advanced Computer Science and Applications.
Niu, Y. (2020). Walmart Sales Forecasting using XGBoost algorithm and Feature engineering. 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE).
Ding, J., Chen, Z., Xiaolong, L., & Lai, B. (2020). Sales Forecasting Based on CatBoost. 2020 2nd International Conference on Information Technology and Computer Application (ITCA).
Islam, D. L., Farooqui, M. F., Khan, A., Wasi, M., & Shaikh, T. (2023). Walmart Sales Analysis and Prediction. International Journal of Advanced Research in Science, Communication and Technology.
Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts.
Singh, B., Kumar, P., Sharma, N., & Sharma, K. P. (2020). Sales Forecast for Amazon Sales with Time Series Modeling. 2020 First International Conference on Power, Control and Computing Technologies (ICPC2T).
Bandara, K., Shi, P., Bergmeir, C., Hewamalage, H., Tran, Q.-H., & Seaman, B. (2019). Sales Demand Forecast in E-commerce using a Long Short-Term Memory Neural Network Methodology. ArXiv.
Zhou, T. (2023). Improved Sales Forecasting using Trend and Seasonality Decomposition with LightGBM. 2023 6th International Conference on Artificial Intelligence and Big Data (ICAIBD).
Pustokhina, I., & Pustokhin, D. A. (2023). A Comparative Analysis of Traditional Forecasting Methods and Machine Learning Techniques for Sales Prediction in E-commerce. American Journal of Business and Operations Research.
[1] A GS1 é uma organização global que desenvolve e implementa padrões para identificação e troca de dados entre empresas, incluindo o controle dos GTINs (Global Trade Item Numbers).
[2] https://otexts.com/fpp3/hts.html
[3] https://business-science.github.io/modeltime/
[4] https://www.nixtla.io/
- Categoria(s): Blog boostrap Machine learning
Palavras relacionadas: cienciadedados, estatistica