Engenharia de prompt Llama
Análise de sentimento climáticos
Introdução
Neste artigo, exploraremos como desenvolver uma engenharia de prompt eficaz utilizando o modelo LLaMA 3 para classificar textos relacionados a condições climáticas. O objetivo principal é categorizar os sentimentos expressos em postagens do Twitter sobre mudanças climáticas em três categorias: positivo, negativo e neutro. A análise permite compreender as percepções e reações das pessoas em relação ao clima do planeta, oferecendo insights valiosos sobre as tendências de opinião pública.
Objetivo
O objetivo do projeto é classificar tweets sobre o tema “Mudanças Climáticas” em categorias de sentimento (positivo, neutro e negativo) utilizando um modelo de linguagem de grande escala (LLM) pré-treinado, especificamente o modelo LLaMA. Essa análise busca identificar tendências e padrões na opinião pública, permitindo uma compreensão mais profunda sobre como as pessoas percebem e reagem às mudanças climáticas. Os insights obtidos podem ser utilizados por organizações ambientais, formuladores de políticas e empresas para melhorar estratégias de comunicação, engajamento e formulação de políticas públicas.
Perguntas-chave
- Quais são os sentimentos predominantes (positivos, neutros ou negativos) expressos em discussões no Twitter sobre mudanças climáticas?
- Como o sentimento público em relação às mudanças climáticas evolui ao longo do tempo?
- Existem eventos ou períodos específicos que provocam mudanças significativas no sentimento público?
- Quais fatores (como hashtags, palavras-chave ou influenciadores) estão associados a sentimentos positivos ou negativos nas discussões sobre mudanças climáticas?
Se você quiser acompanhar o desenvolvimento do projeto, abaixo estão os links para o repositório no GitHub e para a base de dados:
Script e Base de Dados:
Script: O código referente à engenharia de prompt sobre condições climáticas pode ser acessado no link abaixo:
Link do Repositório no GitHub
Base de Dados: Para este projeto, utilizamos uma base disponível no Kaggle:
Link para a Base de Dados no Kaggle
Pré-processamento
Na segunda etapa, foi realizada a limpeza dos dados textuais para garantir que o modelo LLM possa ser aplicado de maneira eficiente e precisa. O dataset original, proveniente do Twitter, continha mais de 9.050 registros. No entanto, para evitar problemas de memória e garantir um processamento mais ágil, o conjunto de dados foi reduzido para 1.000 linhas.
O dataset processado inclui as seguintes colunas principais:
- UserScreenName: Nome de usuário do Twitter.
- UserName: ID da conta.
- Text: Coluna alvo contendo os textos a serem analisados.
A análise inicial revelou que os textos apresentavam diversos caracteres especiais, URLs, menções e outros elementos desnecessários para a tarefa de análise de sentimentos. Por isso, foi essencial realizar uma limpeza cuidadosa dos dados, removendo esses caracteres e padronizando o conteúdo textual. Essa etapa de pré-processamento é fundamental para garantir a qualidade e a consistência dos dados antes da aplicação do modelo LLM.
Aqui está a visualização inicial do nosso dataset, apresentando as colunas e as cinco primeiras linhas de dados. O próximo passo será a criação de uma função para realizar a limpeza desse dataset, garantindo que os textos estejam prontos para análise e para o uso no modelo LLM.


Nesta etapa, foi criada uma função com os seguintes passos para o pré-processamento dos textos:
- Remoção de URLs: Para excluir links presentes nos tweets, que não são relevantes para a análise de sentimentos.
- Remoção de menções (@): Para eliminar referências a outros usuários do Twitter, simplificando o texto.
- Tokenização: Para dividir os textos em palavras individuais, facilitando o processamento posterior.
- Remoção de stopwords: Para eliminar palavras irrelevantes, como artigos, preposições e conjunções, que não agregam significado à análise.
Após aplicar a função ao dataset, obtivemos um conjunto de dados completamente limpo, sem “ruídos” ou elementos desnecessários nos textos. Isso assegura que o modelo LLM possa trabalhar de forma eficiente e precisa. Na terceira etapa, foi realizada uma análise exploratória dos dados. A partir dessa análise, foi possível identificar alguns temas relevantes relacionados às condições climáticas. Esses temas oferecem insights valiosos para compreender as principais preocupações e discussões públicas sobre o clima.
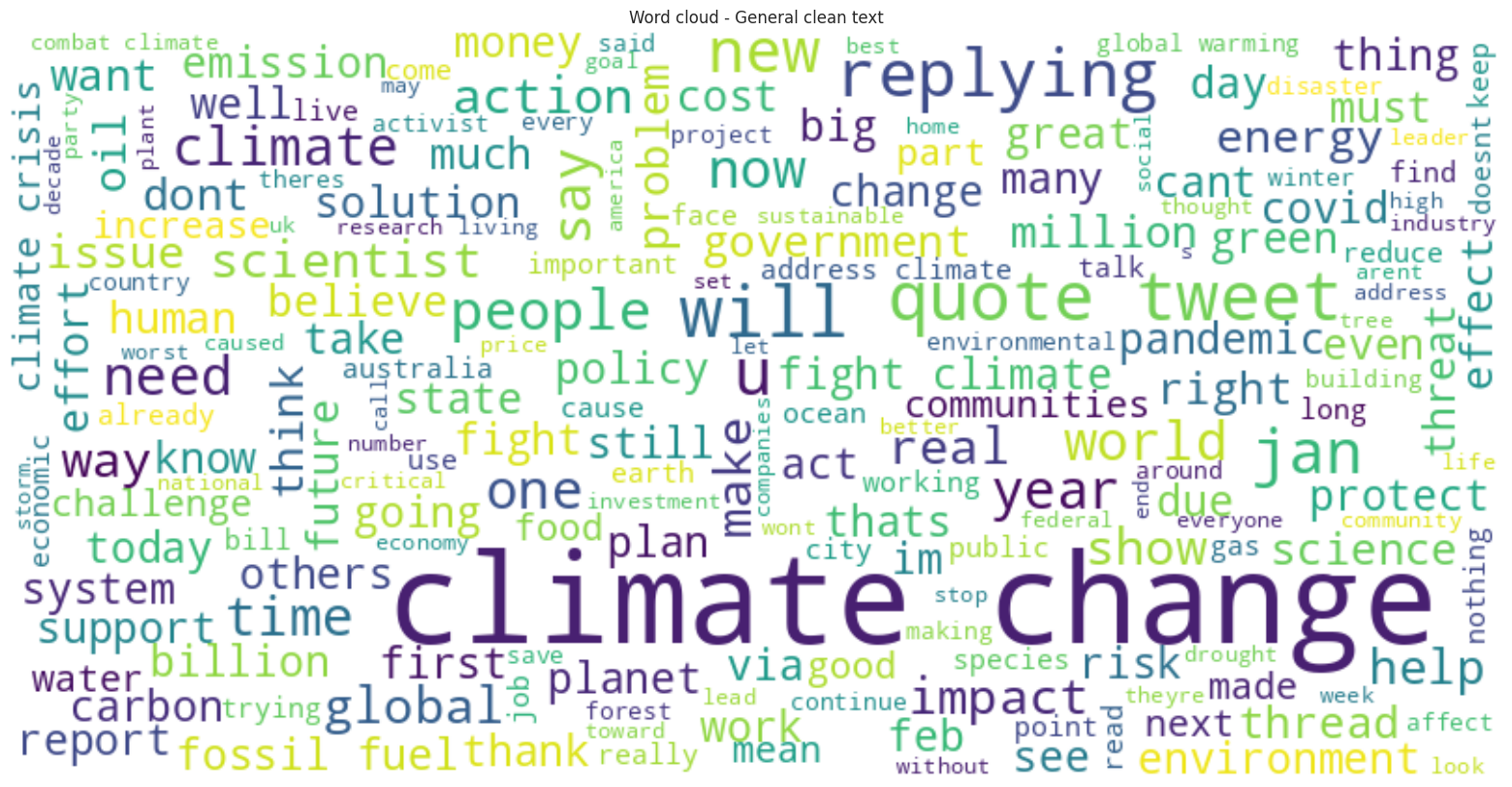
A partir da nuvem de palavras gerada com o texto limpo, é possível identificar palavras-chave que se destacam nas discussões sobre condições climáticas. Termos como “climate change”, “carbon”, “planet”, “fossil fuel”, “government” e “thank” aparecem com maior frequência, refletindo os tópicos centrais abordados pelos usuários. Essas palavras-chave ajudam a entender os principais pontos de discussão e preocupação pública sobre mudanças climáticas, como a emissão de carbono, o impacto dos combustíveis fósseis e as políticas governamentais relacionadas ao clima.
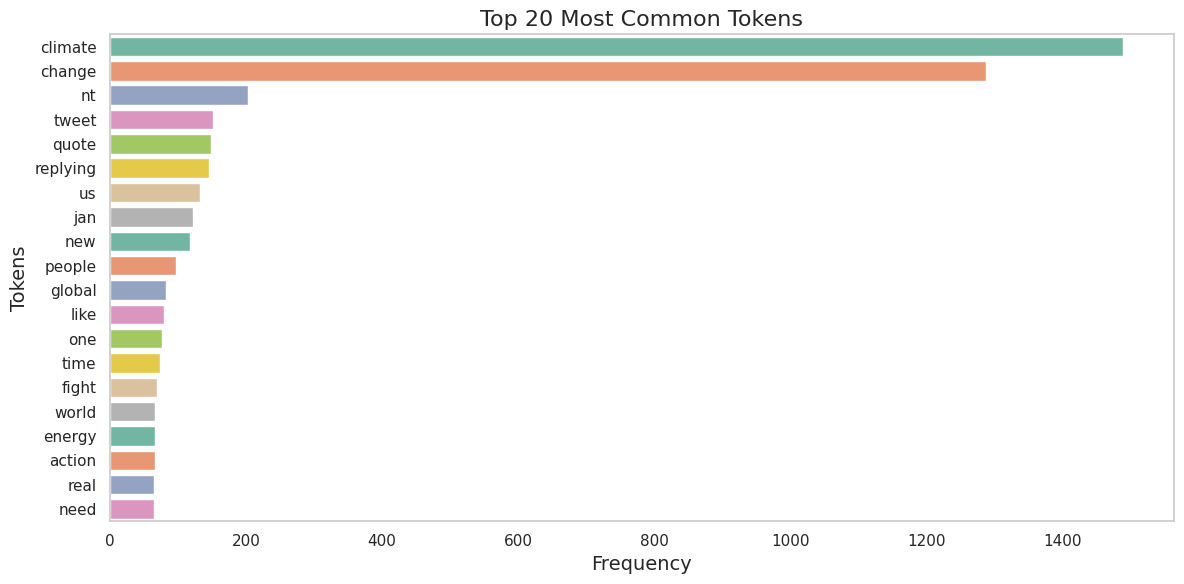
O gráfico acima apresenta os 20 tokens mais comuns nos textos analisados. O termo mais frequente é “climate”, seguido por “change”, refletindo o foco das discussões sobre mudanças climáticas. Outros tokens importantes incluem “tweet”, “global”, “energy”, “action”, e “world”, que destacam temas relevantes como energia, ações climáticas e preocupações globais.
Essa análise de frequência de tokens fornece uma visão clara dos tópicos predominantes nas discussões públicas e ajuda a entender quais aspectos das mudanças climáticas geram mais engajamento e atenção.
Agora avançamos para a terceira parte do projeto, onde utilizamos o modelo de linguagem de grande escala (LLM) LLaMA 3. Nesta etapa, o modelo é aplicado para realizar a tarefa de análise de sentimentos nos textos previamente limpos.
Com o uso de engenharia de prompt, ajustamos o LLaMA 3 para classificar os textos em três categorias de sentimento: positivo, neutro e negativo. Esse processo permite ao modelo interpretar as nuances dos textos relacionados às mudanças climáticas e fornecer resultados que destacam as emoções predominantes em cada mensagem.
O LLaMA 3 foi escolhido devido à sua alta capacidade de lidar com tarefas avançadas de compreensão de linguagem natural, oferecendo precisão e eficiência mesmo em cenários complexos. A aplicação do modelo nessa análise não apenas categoriza os sentimentos, mas também fornece uma base sólida para extrair insights sobre as percepções públicas em relação ao clima e às mudanças ambientais.

(Foto de uma lhama branca com montanhas ao fundo, disponível em Freepik. Licença gratuita.)
Modelo LLM llama
Explicação sobe modelo LLM Llama
O modelo LLM LLaMA (Large Language Model Meta AI) é uma família de modelos de linguagem de grande escala desenvolvida pela Meta AI (anteriormente conhecida como Facebook AI Research). O nome “LLaMA” é um acrônimo para Large Language Model Meta AI. Ele foi projetado para tarefas de processamento de linguagem natural (NLP), como compreensão de texto, geração de texto, resumo, tradução, classificação, entre outras. Ele possui algumas características como alta escalabilidade os modelos LLaMA são treinados em um grande volume de dados textuais, utilizando técnicas avançadas de aprendizado de máquina para capturar padrões complexos de linguagem.
Tem um eficiência comparado a outros modelos de linguagem de grande escala, como GPT ou BERT, o LLaMA é otimizado para ser mais eficiente em termos de computação, permitindo que mesmo versões menores tenham um bom desempenho. Utilizado para pesquisa, o modelo foi lançado com o objetivo de facilitar a pesquisa acadêmica e o desenvolvimento de soluções em NLP, sendo amplamente adotado por pesquisadores em tarefas complexas.
Foi disponibilizada para comunidade com a Meta disponibilizou versões do modelo para pesquisadores e desenvolvedores, promovendo a inovação em inteligência artificial. Algumas aplicações Diversificadas o LLaMA pode ser usado em diversos cenários como análise de sentimentos, geração de conteúdo, tradução automática, respostas a perguntas, classificação de textos.

Aqui estamos instanciando o modelo LLM LLaMA 3.1, configurado com 8 bilhões de parâmetros. Esse modelo é uma versão avançada, que combina alta capacidade de processamento com eficiência computacional, permitindo análises detalhadas e precisas em tarefas complexas de linguagem natural.

Na segunda parte da construção do prompt, estamos instanciando o modelo para ser executado na GPU, garantindo maior eficiência e desempenho na classificação dos textos. A escolha entre GPU é crucial para otimizar o tempo de processamento, especialmente ao lidar com grandes volumes de dados e modelos de alta complexidade, como o LLaMA 3.1. Utilizar a GPU permite que as operações sejam realizadas de forma mais rápida, garantindo uma classificação precisa e ágil dos textos.
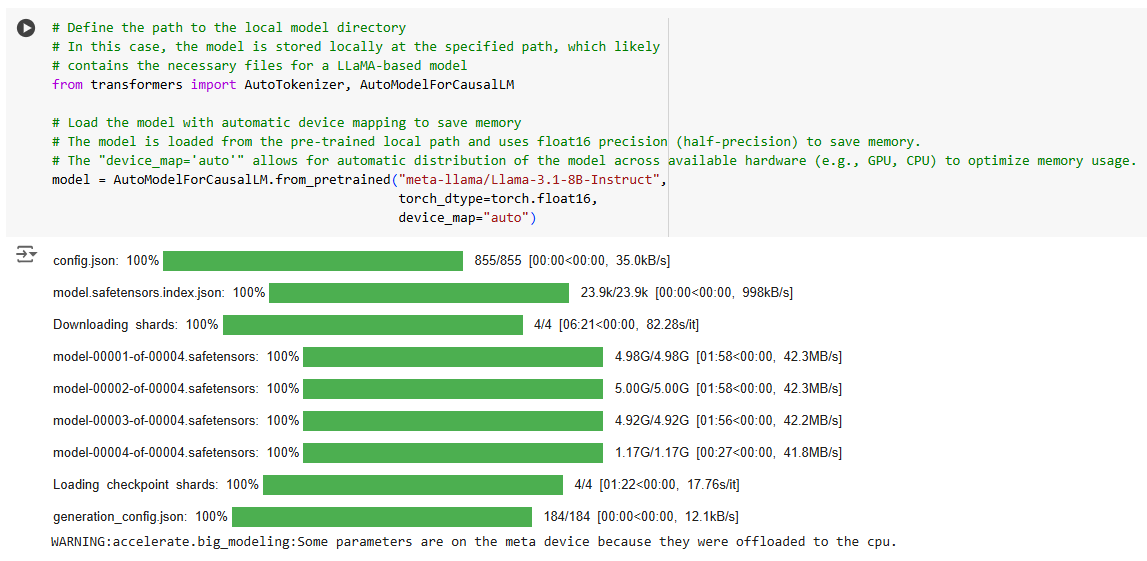
No trecho acima, vemos o modelo LLM LLaMA 3.1 sendo carregado com suporte para execução em GPU, utilizando o parâmetro device_map=’auto’. Esse parâmetro permite que o modelo distribua automaticamente a carga de trabalho entre os dispositivos disponíveis (como GPU e CPU), otimizando o uso da memória e garantindo maior eficiência no processamento.
A precisão de meio ponto flutuante (float16) foi configurada por meio de torch_dtype=torch.float16, reduzindo o uso de memória sem comprometer o desempenho do modelo. Esse ajuste é essencial para carregar grandes modelos como o LLaMA em hardware com recursos limitados.
Graças a essa configuração, o modelo é capaz de realizar tarefas de maneira mais rápida e eficiente, aproveitando ao máximo os recursos de hardware disponíveis.
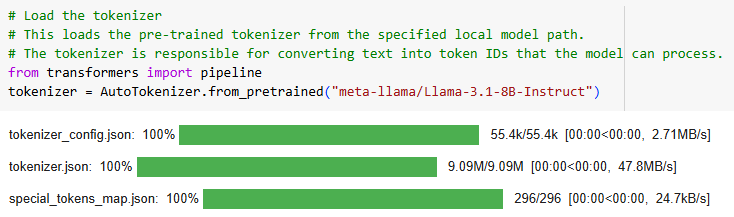
Na terceira parte, estamos carregando o tokenizador do modelo LLM LLaMA 3.1. O tokenizador é uma parte essencial do pipeline de processamento de linguagem natural, responsável por converter o texto em IDs de tokens, que podem ser processados diretamente pelo modelo. No código apresentado, utilizamos o método AutoTokenizer.from_pretrained para carregar o tokenizador pré-treinado associado ao modelo LLaMA 3.1 com 8 bilhões de parâmetros. Esse processo garante que o texto seja tokenizado de forma consistente com o treinamento do modelo, otimizando a compreensão e o desempenho.
Os arquivos carregados incluem:
- tokenizer_config.json: Configurações gerais do tokenizador.
- tokenizer.json: Mapeamento detalhado dos tokens.
- special_tokens_map.json: Mapeamento de tokens especiais, como <pad>, <bos>, e <eos>.
O tokenizador é fundamental para garantir que o texto seja convertido corretamente e de maneira eficiente, alinhado ao funcionamento interno do modelo LLaMA.

Na quarta parte, foi inicializado o pipeline de classificação zero-shot usando o modelo LLM LLaMA 3.1. O pipeline de zero-shot classification permite que o modelo classifique textos em categorias especificadas pelo usuário, sem a necessidade de re-treinamento, utilizando sua capacidade de generalização.
No código apresentado, a inicialização do pipeline foi feita com os seguintes componentes:
- Modelo: O modelo LLaMA previamente instanciado.
- Tokenizador: O tokenizador compatível com o modelo, garantindo uma tokenização adequada dos textos.
Essa configuração é crucial para realizar a classificação de textos em diferentes categorias (por exemplo, sentimentos positivos, neutros e negativos) sem treinamento adicional. O pipeline de classificação zero-shot é ideal para casos em que o modelo precisa interpretar e categorizar informações fora de seu conjunto de treinamento.
Engenharia de prompt
A engenharia de prompt é uma técnica fundamental no uso de modelos de linguagem de grande escala (LLMs, como o LLaMA, GPT e outros). Ela consiste em criar, ajustar e otimizar comandos ou instruções (prompts) que são fornecidos ao modelo para que ele produza respostas ou execute tarefas específicas da forma mais eficiente e precisa possível.
O que é um Prompt?
Um prompt é o texto ou comando inicial fornecido ao modelo para orientá-lo na geração de uma resposta. Por exemplo, em uma análise de sentimento, um prompt poderia ser algo como:
“Classifique o seguinte texto como positivo, negativo ou neutro: ‘Estou muito feliz com as mudanças no clima’.”
Engenharia de Prompt: Por que é importante?
Os modelos de linguagem são treinados em grandes quantidades de dados textuais e possuem uma capacidade de generalização impressionante. No entanto, o comportamento do modelo pode variar dependendo de como a tarefa é apresentada. A engenharia de prompt busca aproveitar ao máximo o potencial do modelo ajustando os prompts para obter respostas mais consistentes e alinhadas com os objetivos.
Como funciona?
A engenharia de prompt envolve as seguintes práticas:
- Formulação clara e específica:
Um prompt bem projetado deve ser claro e direto, fornecendo ao modelo informações suficientes para que ele compreenda a tarefa.
Exemplo ruim: “Fale sobre isso.”
Exemplo bom: “Explique por que a energia renovável é importante para combater mudanças climáticas.”
- Uso de exemplos (Few-Shot Learning):
Fornecer exemplos de entrada e saída no prompt ajuda o modelo a entender o padrão esperado.
Entrada: “Texto: ‘O dia está ensolarado e bonito.’ Sentimento: Positivo.”
Entrada: “Texto: ‘O trânsito hoje foi insuportável.’ Sentimento: Negativo.”
Pergunta: “Texto: ‘Adoro passear no parque durante o outono.’ Sentimento:”
- Instruções Zero-Shot:
O modelo é solicitado a realizar a tarefa sem exemplos prévios, apenas com uma descrição da tarefa no prompt.
Exemplo: “Classifique o seguinte texto em positivo, negativo ou neutro: ‘Hoje está muito quente para trabalhar.’.”
- Ajuste fino do prompt (Prompt Tuning):
Pequenas mudanças na estrutura do prompt, como a escolha das palavras ou a ordem das instruções, podem impactar significativamente os resultados.
- Adição de contexto:
Prompts podem incluir informações adicionais para orientar melhor o modelo.
Exemplo:
“Como um especialista em mudanças climáticas, explique o impacto do derretimento das calotas polares.”
- Iteração e avaliação:
A engenharia de prompt é um processo iterativo, onde os prompts são ajustados e testados repetidamente para melhorar os resultados.
Aplicações da Engenharia de Prompt
- Classificação de Sentimentos: Identificar emoções em textos (positivo, negativo, neutro).
- Geração de Texto: Criar resumos, histórias ou explicações detalhadas.
- Tradução Automática: Converter texto de uma língua para outra.
- Extração de Informações: Identificar entidades específicas (nomes, datas, locais) em um texto.
- Assistentes Virtuais: Responder perguntas e realizar tarefas.
Por que é essencial para LLMs como LLaMA?
A engenharia de prompt é crucial porque os modelos de linguagem não possuem conhecimento contextual sobre a tarefa até que isso seja explicitamente fornecido no prompt. Um bom prompt pode:
- Aumentar a precisão das respostas.
- Reduzir a necessidade de treinamento adicional.
- Economizar recursos computacionais.
- Adaptar o modelo a diferentes tarefas rapidamente.

Aqui estamos definindo uma função para criar o prompt, que será usado pelo modelo LLaMA 3.1 para realizar a classificação de sentimentos.
Essa função organiza e estrutura o texto de entrada de forma que o modelo possa interpretar corretamente a tarefa e retornar uma resposta coerente.
A estrutura do prompt pode incluir os seguintes elementos:
- Descrição da tarefa: Uma explicação clara do que o modelo deve fazer.
Exemplo: “Classifique o seguinte texto em um dos sentimentos: positivo, negativo ou neutro.”
- Texto a ser classificado: O texto de entrada fornecido ao modelo.
Exemplo: “Texto: ‘Estou muito satisfeito com as mudanças recentes.’.”
- Opções de classificação: As categorias possíveis para a saída.
Exemplo: “Escolha entre: Positivo, Negativo, Neutro.”
Ao utilizar essa função, garantimos que o modelo receba instruções claras e bem formatadas, maximizando a precisão na classificação de sentimentos.

Aqui temos um exemplo de engenharia de prompt, onde o modelo é solicitado a responder à seguinte pergunta:
“O que o Telescópio James Webb estava procurando no espaço?”
Essa abordagem demonstra como um prompt bem formulado pode guiar o modelo a fornecer respostas precisas e informativas. O modelo interpreta a pergunta e utiliza seu conhecimento pré-treinado para gerar uma resposta.

Por que é um exemplo de engenharia de prompt ?
- A pergunta foi clara e específica, garantindo que o modelo compreenda o contexto.
- A instrução adicional orienta o modelo a responder de forma objetiva e informativa.
- O prompt utiliza palavras-chave como “Telescópio James Webb” e “espaço”, que ajudam o modelo a buscar informações relevantes em seu conhecimento.
Esse tipo de abordagem é útil para explorar tópicos científicos e extrair informações detalhadas de modelos de linguagem como o LLaMA.
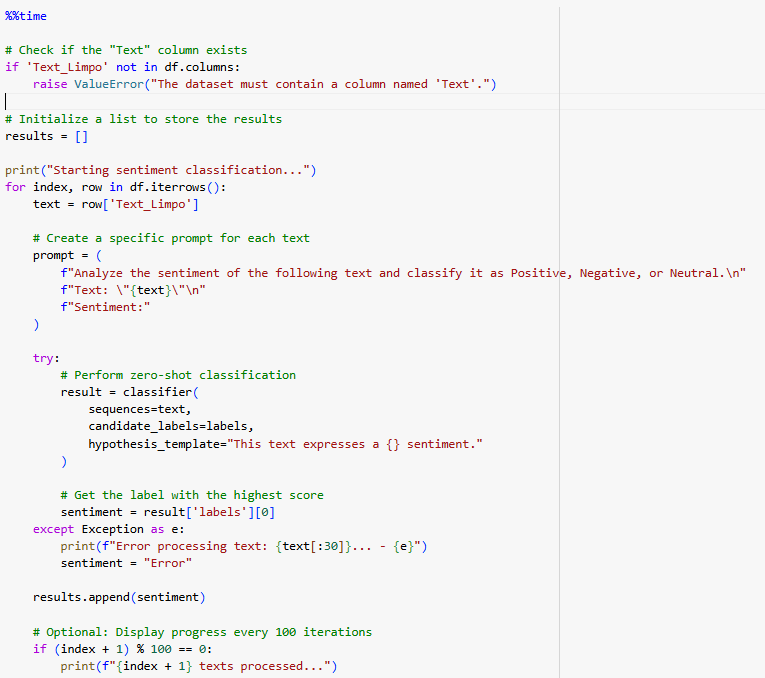
Neste trecho de código, é utilizado um prompt personalizado para realizar a análise de sentimentos em textos, classificando-os como positivo, neutro ou negativo. A lógica do código é estruturada para processar os textos de um dataframe e aplicar a classificação usando o pipeline classifier. O código verifica se a coluna Text_Limpo existe no dataframe. Caso contrário, uma mensagem de erro é levantada.
Isso garante que a estrutura do dataset está correta antes de iniciar o processamento. Uma lista vazia chamada results é criada para armazenar os sentimentos classificados de cada texto. Com o uso de df.iterrows(), o código itera sobre cada linha do dataframe. Em cada iteração, o texto da coluna Text_Limpo é extraído para análise.
Para cada texto, é gerado um prompt específico com uma estrutura clara e objetiva, como: Analyze the sentiment of the following text and classify it as Positive, Negative, or Neutral. Essa abordagem orienta o modelo sobre o que deve ser feito.
O pipeline classifier realiza a classificação com as seguintes configurações sequences recebe o texto a ser classificado.andidate_labels define as categorias de classificação (Positivo, Neutro, Negativo).
Resultado
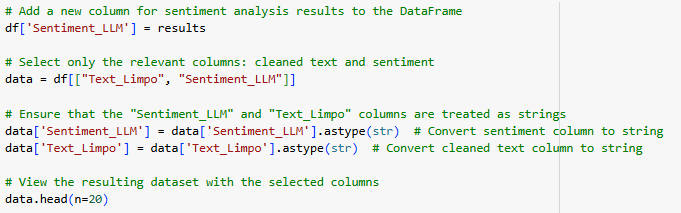

Nesta etapa, temos o resultado final da classificação de sentimentos realizada pelo modelo LLM LLaMA, utilizando a engenharia de prompt previamente configurada. O modelo foi capaz de analisar os textos da coluna Text_Limpo e classificar os sentimentos como positivo, negativo ou neutro passo a passo do processo:
Adição de uma nova coluna para os resultados a coluna Sentiment_LLM foi criada no dataframe original (df) para armazenar os resultados das classificações.
Seleção de colunas relevantes apenas as colunas Text_Limpo (textos limpos) e Sentiment_LLM (sentimentos classificados) foram selecionadas para facilitar a análise.
Conversão de colunas para strings as colunas Sentiment_LLM e Text_Limpo foram convertidas para o tipo string, garantindo consistência no formato dos dados.
Com base nos resultados, podemos afirmar que o modelo conseguiu capturar as nuances dos textos e atribuir classificações coerentes aos sentimentos. Isso demonstra a eficácia da engenharia de prompt utilizada, que forneceu instruções claras e específicas ao modelo. A categorização obtida pode ser usada para gerar insights valiosos sobre as percepções públicas em relação aos temas analisados.
Aqui nessa função é usada para gerar uma nuvem de palavras a partir de um texto. As nuvens de palavras são representações visuais que destacam as palavras mais frequentes em um conjunto de texto, com o tamanho das palavras proporcional à sua frequência.
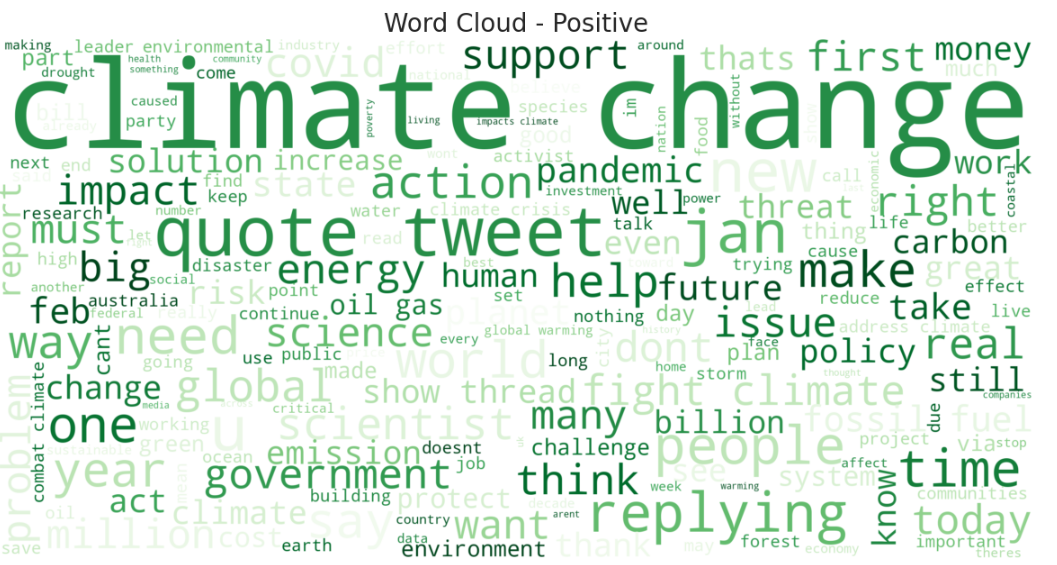

As nuvens de palavras geradas mostram uma análise visual dos termos mais frequentes para cada categoria de sentimento: Negativo, Neutro e Positivo. Essas visualizações permitem identificar as principais palavras-chave associadas aos sentimentos sobre mudanças climáticas, fornecendo insights sobre como o modelo LLM classificou os textos.
Análise por Sentimento
Nuvem de Palavras – Sentimentos Neutros
Principais palavras-chave: “climate”, “change”, “relying”, “energy”, “problem”.
Interpretação: Os textos neutros parecem abordar questões gerais sobre o clima, sem carregar emoções extremas, como em discussões descritivas ou informativas.
Nuvem de Palavras – Sentimentos Negativos:
Principais palavras-chave: “climate”, “change”, “crisis”, “disaster”, “issues”.
Interpretação: Os textos classificados como negativos frequentemente mencionam crises climáticas, problemas ambientais e aspectos catastróficos relacionados ao clima.
Nuvem de Palavras – Sentimentos Positivos:
Principais palavras-chave: “climate”, “change”, “solution”, “action”, “support”, “future”.
Interpretação: Os textos positivos destacam ações e soluções para combater as mudanças climáticas, bem como mensagens de otimismo sobre o futuro.
Conclusão
Este estudo destacou como a engenharia de prompt e o modelo LLM LLaMA 3.1 podem ser ferramentas poderosas para a análise de sentimentos em discussões sobre mudanças climáticas. Utilizando uma abordagem estruturada que incluiu pré-processamento, construção de prompts personalizados e classificação zero-shot, conseguimos classificar textos em três categorias de sentimento: positivo, neutro e negativo. Essa análise trouxe à tona percepções valiosas sobre como as mudanças climáticas são discutidas e compreendidas publicamente.Os resultados demonstraram a capacidade do modelo de identificar padrões relevantes nos textos analisados.
Por exemplo:
- Textos positivos frequentemente enfatizaram soluções, ações climáticas e otimismo, utilizando palavras como “solution”, “action” e “future”.
- Textos negativos refletiram preocupações, crises e problemas relacionados ao clima, com termos como “crisis”, “disaster” e “issues”.
- Textos neutros apresentaram uma visão mais descritiva, focando em termos como “energy”, “problem” e “global”.
Além disso, as nuvens de palavras forneceram uma representação visual clara dos tópicos centrais em cada categoria, facilitando a interpretação e identificação de tendências. A eficácia da engenharia de prompt foi evidenciada na clareza e consistência das classificações. Essa técnica mostrou-se essencial para maximizar o desempenho do modelo LLaMA, permitindo que ele interpretasse nuances linguísticas e gerasse respostas altamente precisas. A utilização de recursos avançados, como processamento em GPU e configurações otimizadas de memória (float16), garantiu a eficiência do processo, mesmo ao lidar com grandes volumes de dados.
Impacto e Implicações
Este trabalho reforça o potencial de modelos de linguagem de grande escala (LLMs) para transformar a maneira como interpretamos dados textuais em contextos críticos, como as mudanças climáticas. As descobertas aqui apresentadas têm implicações importantes:
- Comunicação Estratégica: Os insights podem ser utilizados por organizações ambientais e empresas para criar campanhas de conscientização e engajamento mais eficazes.
- Políticas Públicas: A análise de sentimentos pode orientar formuladores de políticas ao identificar preocupações públicas específicas e períodos de maior engajamento social.
- Pesquisa Científica: A metodologia empregada pode servir como base para estudos em outros domínios, como saúde, educação e tecnologia.
Limitações e Próximos Passos
Embora os resultados sejam promissores, algumas limitações foram identificadas:
- Volume de Dados: A redução do dataset para 1.000 linhas, devido a restrições de memória, pode ter limitado a abrangência da análise.
- Contexto Cultural e Linguístico: O modelo foi aplicado apenas a textos em inglês, o que pode não capturar nuances culturais de discussões em outras línguas.
Para estudos futuros, recomenda-se:
- Expandir o dataset para incluir textos de diferentes idiomas e contextos culturais.
- Integrar técnicas de aprendizado contínuo (fine-tuning) para adaptar o modelo a domínios específicos.
- Explorar combinações com modelos multimodais para integrar análises de texto com imagens, como gráficos climáticos e mapas.
Contribuição Final
Este estudo apresenta um exemplo prático e aplicável do uso de LLMs em análise de sentimentos, demonstrando sua relevância na era da inteligência artificial. Ao integrar avanços tecnológicos, como o modelo LLaMA 3.1, e métodos analíticos robustos, como a engenharia de prompt, pavimentamos o caminho para novas formas de explorar e compreender dados textuais complexos.
Assim, concluímos que ferramentas baseadas em LLMs não apenas ajudam a interpretar sentimentos, mas também fornecem suporte estratégico para enfrentar desafios globais, como as mudanças climáticas, com mais clareza e precisão.
Referencia model LLM
META AI. LLaMA: Large Language Model Meta AI. 2023. Disponível em: https://ai.facebook.com/blog/large-language-model-llama. Acesso em: 22 nov. 2024.
BROWN, T.; MANN, B.; RYDER, N.; SUBBIAH, M.; KAPLAN, J.; DHARIWAL, P.; NEELAKANTAN, A.; SHYAM, P.; SASTRY, G.; ASKELL, A.; AGARWAL, S.; HERBERT-VOSS, A.; KRUEGER, G.; HENIGHAN, T.; CHILD, R.; RAMESH, A.; ZIEGLER, D.; WU, J.; WINTER, C.; HESSE, C.; CHEN, M.; SIGLER, E.; LITWIN, M.; GRAY, S.; CHESS, B.; CLARK, J.; BERNER, C.; MCCANDLISH, S.; RADFORD, A.; SUTSKEVER, I.; AMODEI, D. Language Models are Few-Shot Learners. 2020. Disponível em: https://arxiv.org/abs/2005.14165. Acesso em: 22 nov. 2024.
Links complementares:
Notebook GitHub:
https://github.com/RafaelGallo/LLM_Engineering_prompt_LLama3_Sentiment_analysis_climate/tree/main
Base de dados: https://www.kaggle.com/datasets/die9origephit/climate-change-tweets/data
Por Rafael Gallo
- Categoria(s): Blog ChatGPT Ciências de dados dados ambientais data visualization Estatística Estatística
Palavras relacionadas: cienciadedados, estatistica