Exploração de Dados, ou import numpy as np ?
A importância dos fundamentos estatísticos, algébricos e econométricos para o sucesso de projetos em Data Science

Muitos daqueles que se intitulam Cientista de Dados, a profissão mais sexy do Século XXI (Davenport e Patil, 2012, Harvard Business Review), focam suas atividades em programação e, por vezes, não se preocupam com a preparação e estruturação do dataset, com o diagnóstico preliminar acerca do comportamento dos dados e/ou com a sua exploração visual, por meio de gráficos estáticos ou dinâmicos.
Muitos inclusive usam códigos previamente desenvolvidos e disponíveis na web, ou simplesmente os adaptam às suas realidades, para fazer posts em redes sociais com o intuito de receber a maior quantidade de likes, sem que os fundamentos estatísticos, algébricos ou econométricos (fundamentos de analytics, em essência) sejam levados em consideração.
Temos observado uma quantidade já enorme e crescente de posts e cursos online que fazem uso de códigos de programação em R, em Python, ou em qualquer outra plataforma (open ou não), referentes a determinadas técnicas (supervised ou unsupervised) que requerem, em suas premissas, características específicas das variáveis em uso.
Pois bem, ao analisarmos o que está sendo proposto, verificamos que parte daquelas variáveis (ou, às vezes, a totalidade delas) não obedece aos critérios fundamentais da técnica, mas estão sendo utilizadas e inseridas, por meio de códigos, na programação. Será que o famigerado “AutoML” vai nos trazer soluções mágicas? O que o modelo irá gerar como outputs? Como interpretá-los? Como utilizar estes outputs para classificação ou predição e, consequentemente, para tomada de decisão?
Muitos destes “Cientistas de Dados” priorizam o código, a programação, em detrimento dos fundamentos de estatística, álgebra, pesquisa operacional, econometria. Por que será? Talvez porque uma enormidade de códigos prontos já esteja disponível e seja de fácil acesso? Ou porque o ganho de tempo gerado por este caminho é considerável? Com certeza, estes são motivos que temos escutado constantemente no mercado e na academia. Entretanto, acredite, este é um modo muito fácil de fazer com que seu currículo fique desatualizado em um futuro não tão distante! Uma carreira em ascensão não pode correr tão sérios riscos!
O investimento de tempo no estudo dos fundamentos não é baixo, porém é a melhor e mais eficaz maneira de consolidar uma trajetória na Ciência de Dados. Sem fundamentos e sem uma base conceitual sólida, todo o resto torna-se muito mais suscetível a virar pó.
Se um software ou uma linguagem de programação deixarem de ser utilizados, ou forem gradualmente substituídos por outros (por razões de mercado, eficiência computacional, entre outros motivos), os fundamentos e conceitos continuarão a existir e servirão de base para uma adaptação do profissional de maneira mais fácil e ágil. Enquanto isso, aqueles que se ativeram, apenas e tão somente, a linguagens de programação e códigos específicos terão muito mais dificuldades de se enquadrar em novos cenários.
Recentemente, Conor Lazarou escreveu um artigo brilhante (from sklearn import *, 2020) sobre estes pontos. Este artigo está muito relacionado com um fato que aconteceu no final de 2019. Vamos a essa história!
Estava eu, Fávero, em uma reunião em determinado banco de investimentos quando um analista me confessa que havia desenvolvido um código de programação que estimava um modelo preditivo bastante “eficiente” (não sei o que ele quis dizer com o termo “eficiente”) para o comportamento das ações de determinada empresa. Inclusive ele já havia rodado o código e estimado os parâmetros deste modelo (construído a sua equação preditiva) e calculado o seu famoso R² (coeficiente de determinação, também conhecido por coeficiente de ajuste em modelos regressivos). Demonstrei interesse e perguntei o que ele pretendia fazer com os achados.
Ele me respondeu que iria passar para a área de recomendação de carteiras, visto que os ganhos seriam muito interessantes nos meses seguintes para aquele papel de renda variável… se olharmos a carteira recomendada de ações para compra a partir de Janeiro/2020 por parte daquele banco de investimentos, lá estará o famigerado papel daquela empresa. Como sabemos, os ganhos não existiram nos meses seguintes e, para piorar, entramos numa fase extremamente triste da história humana em decorrência do coronavírus.
Na figura a seguir mostramos o quão perigoso pode ser uma abordagem ingênua, que foca em códigos e programação, e que não leva em consideração a elaboração de diagnósticos exaustivos e a construção de gráficos em suas fases preliminares.
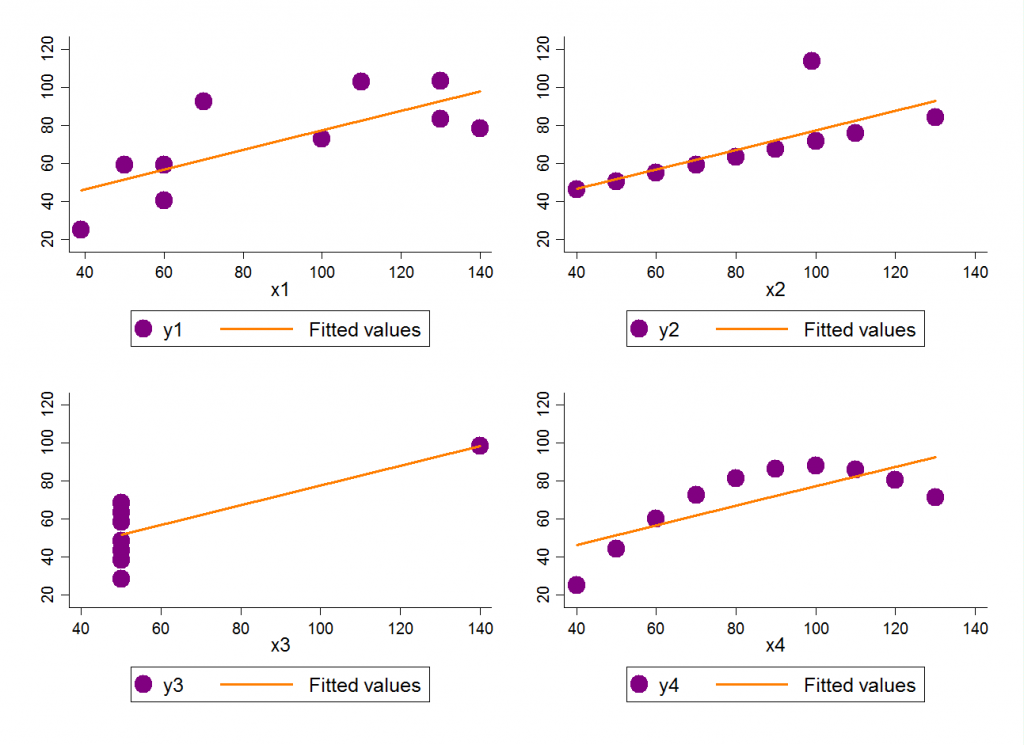
FONTES: Adaptado de Conor Lazarou (2020)
e de Anscombe’s Quartet (Wikimedia Commons).
{kind=link}
Mesmo que os comportamentos dos pontos sejam bastante diferentes, os quatro gráficos apresentam a mesma equação preditiva (fitted values para y ~ x) e a mesma correlação entre y e x (e, portanto, o mesmo valor de R², já que o coeficiente de ajuste representa a correlação ao quadrado entre y e x, ou o percentual de variância de y condicional ao comportamento de variação de x). Em outras palavras, apenas uma equação e uma estatística de ajuste do modelo (no caso, o R²) não oferecem suporte à melhor decisão em termos preditivos (e, nem tampouco, classificatórios). Será que se estudando apenas programação, haverá condições de se interpretar corretamente os outputs obtidos? Como solucionar esses e outros problemas conceituais, sem que se tenha base estatística ou econométrica?
Como afirma o próprio Conor Lazarou, se você não visualizar seus dados e confiar em estatísticas resumidas, poderá erroneamente pensar que esses quatro datasets têm a mesma distribuição, quando um olhar superficial mostra que esse, obviamente, não é o caso. Enquanto no segundo e no terceiro gráficos um (e apenas um) outlier gera um viés no parâmetro de inclinação (conhecido por b, ou coeficiente angular) da variável x, o quarto gráfico mostra que a especificação linear nem é a melhor para fins de ajuste do modelo (no caso, temos uma forma funcional quadrática).
Além disso, também podemos propor a seguinte reflexão: cada ponto distante nos gráficos 2 e 3 representa um outlier ou um ponto influente? Posso removê-lo ou não? Sem as devidas técnicas estatísticas, não conseguiremos elaborar essa distinção. Enquanto o ponto com comportamento discrepante no segundo gráfico pode ser resultado, por exemplo, de alguma sazonalidade, o ponto discrepante no terceiro gráfico pode ser consequência de um erro de medição, da inserção equivocada de dados no dataset, ou até mesmo de um equipamento mal calibrado. Quando devemos eliminar do dataset aqueles dados discrepantes? Qual a pergunta de pesquisa que se está avaliando? Códigos não trarão estas respostas, porém fundamentos e conceitos que embasam a construção destes códigos, sim, o farão.
A visualização de dados permite identificar tendências, outliers, distribuições e formas funcionais nos dados. A ausência desta etapa faz com que todo o restante do projeto de predição ou classificação corra sério risco!
Muito se fala, hoje em dia, em soluções automatizadas por meio das plataformas de “AutoML” que recebem quaisquer tipos de dados e, como consequência, estimam modelos e elaboram predições que, por vezes, são consideradas as mais acuradas possíveis. Será mesmo que, sem a devida preparação dos dados e o devido tratamento das variáveis (data prep e data quality), sem uma adequada análise exploratória dos dados, sem um processo adequado de modelagem estatística e econométrica e, obviamente, sem uma boa conversa (no mínimo) com os profissionais envolvidos no processo de gestão e tomada de decisão, é possível que sejam atingidos resultados satisfatórios e acurados? Acreditamos, em nossa humilde opinião, que não!
Em resumo:
– Explore e limpe seus dados. Preparação e diagnóstico são fundamentais!
– Construa gráficos exaustivamente. Eles te mostrarão muitos comportamentos que os datasets, pura e simplesmente, não o farão.
– Entenda profundamente como cada modelo trabalha e como estima os parâmetros. Tenha erudição em Ciência de Dados!
– Compreenda o que há por trás dos códigos!
– Escolha o modelo apropriado com base nas características das variáveis. Analise as métricas destas variáveis, defina baselines e identifique missing values e outliers (mesmo que não vá fazer nada com eles).
– Estude como os testes estatísticos podem auxiliar na escolha de determinados modelos ou parâmetros de modelagem. Entenda os conceitos relativos a cada indicador de eficiência de modelos, a fim de que se possa escolher aquele mais ajustado, quando isso for possível (o que significa AIC, BIC, R², p-value, -2.LL, ROC, K-S, GINI, entre outros indicadores).
– Por vezes um modelo parcimonioso oferecerá capacidades classificatórias ou preditivas tão boas quanto um modelo teoricamente mais complicado, ou que eventualmente esteja “mais na moda”. Evite o clássico fenômeno do “efeito manada” em Ciência de Dados!
Então disse Deus: π, i, 0 e 1, e fez-se o Universo.
Leonhard Euler
*Luiz Paulo Fávero e Thiago Marques
esse artigo foi realizado originalmente no IT Forum 365: https://itforum365.com.br/colunas/exploracao-exaustiva-de-dados-ou-import-numpy-as-np/
#estatística #ciênciadedados #programação
- Categoria(s): Ciência de dados Estatística Variados